专栏原创出处:github-源笔记文件 (opens new window) ,github-源码 (opens new window),欢迎 Star,转载请附上原文出处链接和本声明。
# 1、前言
spark 内存管理源码说明
- spark-core jar 中
org.apache.spark.memory负责内存管理 - spark-unsafe jar 中
org.apache.spark.unsafe负责内存分配
# 2、堆内存和堆外内存
堆内存和堆外内存:ON_HEAP 和 OFF_HEAP。
- 堆内存表示使用 JVM 管理的内存。
- 堆外内存使用系统平台管理的内存。堆外内存在 Spark 中可以从逻辑上分成两种: 一种是 DirectMemory(直接内存), 一种是 JVM Overhead(下面统称为 off heap)
为什么使用堆外内存)
为了进一步优化内存的使用以及提高 Shuffle 时排序的效率,Spark 引入了堆外(Off-heap)内存,使之可以直接在工作节点的系统内存中开辟空间, 存储经过序列化的二进制数据。除了没有 other 空间,堆外内存与堆内内存的划分方式相同,所有运行中的并发任务共享存储内存和执行内存。
Spark 1.6 开始引入了 Off-heap memory(详见 SPARK-11389 (opens new window) )。 这种模式不在 JVM 内申请内存,而是调用 Java 的 unsafe 相关 API 。由于这种方式不经过 JVM 内存管理,所以可以避免频繁的 GC。
优点是:Spark 可以直接操作系统堆外内存,减少了不必要的内存开销,以及频繁的 GC 扫描和回收,提升了处理性能。堆外内存可以被精确地申请和释放,而且序列化的数据占用的空间可以被精确计算,所以相比堆内内存来说降低了管理的难度,也降低了误差。
缺点是:必须自己编写内存申请和释放的逻辑。
# 3、内存划分
Spark-(1.6.0 ~ pre3.0.0)之前 org.apache.spark.memory.MemoryManager 有 2 个实现类,UnifiedMemoryManager
(静态内存管理) 和 StaticMemoryManager(统一内存管理)。
Spark-1.6.0 中,引入了一个新的参数 spark.memory.userLegacyMode(默认值为 false),表示不使用 Spark-1.6.0 之前的内存管理机制 (StaticMemoryManager)。
Spark 3 已经废弃该参数且删除了 StaticMemoryManager 类。因此我们现在分析的内存模型为 UnifiedMemoryManager 实现的统一内存管理。
Spark 在 MemoryMode 定义了两种内存类型,堆内存和堆外内存:ON_HEAP 和 OFF_HEAP。
Spark 定义了一个抽象类 MemoryPool 对内存进行管理,它需要一个保证线程安全的锁对象 lock,还有一个成员属性就是内存池的大小 _poolSize。该抽象类还定义了一些方法:获取内存池的大小、获取已用内存的大小、获取空余内存的大小、为内存池扩展指定 delta 大小的空间 (delta 必须为正整数)、将内存池缩小指定大小 delta 的空间 (delta 必须为正整数,且缩小后的空间大小要大于已经使用的空间大小)。
MemoryPool 有两个实现类,一个为存储体系服务 (storage),另一个为计算引擎服务 (execution)。
StorageMemory 和 ExecutionMemory 存在动态占用的机制。任何一方资源不足时都可以占用另一方空余的资源。 当 Storage 占用了 Execution 的资源后,如果 Execution 需要更多的计算资源,会将 Storage 所占用的资源强行回收(转存硬盘);相反,如果 Execution 占用了 Storage 的资源后,Storage 需要更多的存储资源时,无法强行回收 Execution 占用的资源(考虑 Shuffle 等多种因素)。
# 3.1 相关参数
spark.driver.memory(默认 1g)driver 端分配的内存
spark.driver.memoryOverhead(每个 driver 分配的 non-heap memory)
spark.executor.memory(默认 1g)每个 executor 分配的内存
spark.executor.memoryOverhead (cluster mode 模式下每个 executor 分配的 non-heap memory)
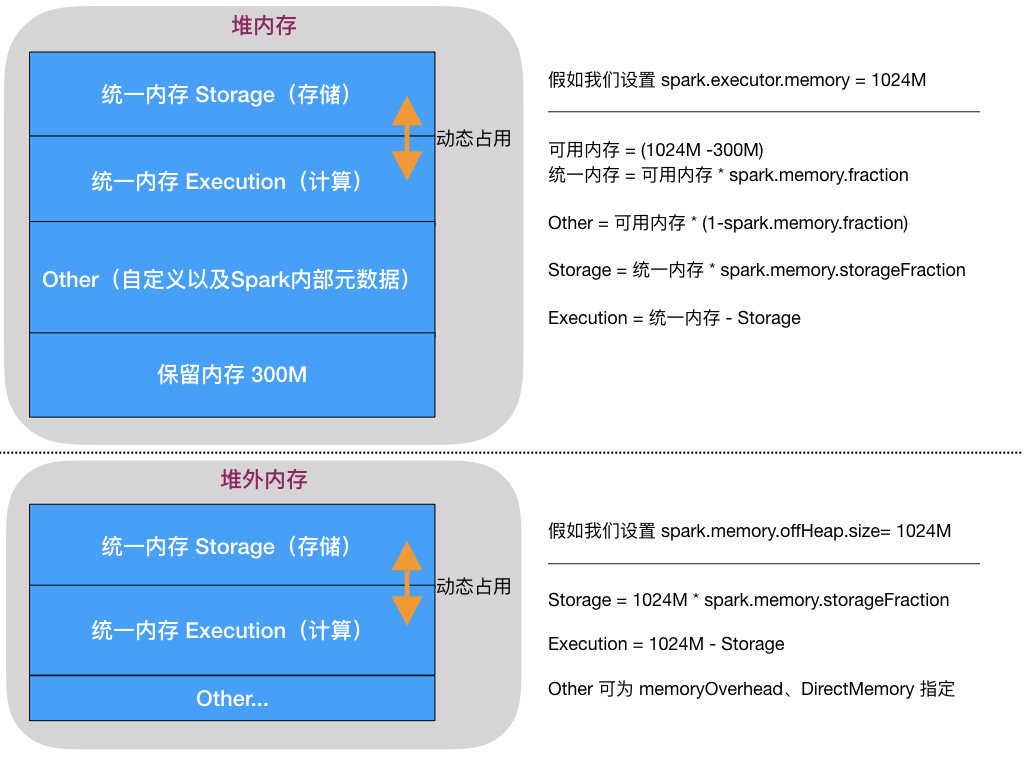
spark.memory.fraction (默认 0.6)executor 上用作 storage&execution 的内存占比,剩余的用于代码层面的存储
spark.memory.storageFraction (默认 0.5)executor 上用作 storage 的内存占比,剩余的用于 execution
spark.memory.offHeap.enabled (默认为 false)是否开启堆外内存
spark.memory.offHeap.size (默认为 0)如果开启对外内存,设置堆外大小
Spark 3 以前废弃及无用参数说明
spark.memory.useLegacyMode (!3.0 废弃配置),3.0 前配置为 true 将使用`StaticMemoryManager`进行内存管理
spark.storage.safetyFraction (默认 0.9)(!spark3 中未使用该参数控制动态占用)
# 3.2 内存划分示意图
# 4、相关源码解读
MemoryManager 中定义了堆内堆外 4 个 MemoryPool(Storage&Execution 各 2 个),所有内存的管理通过该类管理。以下是相关类型的内存申请释放方法:
//申请存储内存
def acquireStorageMemory(blockId: BlockId, numBytes: Long, memoryMode: MemoryMode): Boolean
//申请展开内存
def acquireUnrollMemory(blockId: BlockId, numBytes: Long, memoryMode: MemoryMode): Boolean
//申请执行内存
def acquireExecutionMemory(numBytes: Long, taskAttemptId: Long, memoryMode: MemoryMode): Long
//释放存储内存
def releaseStorageMemory(numBytes: Long, memoryMode: MemoryMode): Unit
//释放执行内存
def releaseExecutionMemory(numBytes: Long, taskAttemptId: Long, memoryMode: MemoryMode): Unit
//释放展开内存
def releaseUnrollMemory(numBytes: Long, memoryMode: MemoryMode): Unit
MemoryPool 内存池有 StorageMemoryPool 与 ExecutionMemoryPool 2 个实现类
- ExecutionMemoryPool 中记录了 taskId 与其使用的内存大小
- StorageMemoryPool 中记录了当前使用大小以及存储的内容 MemoryStore
# 4.1 UnrollMemory 理解
将 Partition 由不连续的存储空间转换为连续存储空间的过程,Spark 称之为"展开"(Unroll)。
我们使用迭代器一条一条获取数据时,事先不知道占用内存的大小,只能一边迭代一边申请内存。全部迭代完成后将 UnrollMemory 转为 StorageMemory。
UnrollMemory 是 StorageMemory 内部的一部分。
# 参考
