专栏原创出处:github-源笔记文件 (opens new window) ,github-源码 (opens new window),欢迎 Star,转载请附上原文出处链接和本声明。
# 1. 简介
# Spark 的身世
Spark (opens new window) 是一个通用的并行计算框架,由加州伯克利大学(UC Berkeley)的 AMP 实验室开发于 2009 年,并于 2010 年开源,2013 年成长为 Apache 旗下在大数据领域最活跃的开源项目之一。
目前 Spark 的版本已经更新到了 2.4.5,并且预上线了 3.0 版本,相信未来会有更精彩的地方值得我们期待。
# Spark 特性
快速):采用先进的 DAG 调度程序,查询优化器和物理执行引擎,实现了批处理和流数据处理的高性能,比 Hadoop 的 Map-Reduce 计算速度提升了很多倍。
易使用):支持多种编程语言,比如:Java、Scala、Sql、Python、R。提供了 80 多个高级操作符,可以轻松构建并行应用程序,并且可以在 Scala、Python、R 和 SQL shell 中交互式地使用它。
通用性):提供了一套完善的生态体系,支持交互式查询,流处理,批处理,机器学习算法和图形处理,可以在同一个应用程序中无缝的组合使用他们。
到处运行):支持单机、YARN、Mesos 等多种部署方式,并且支持丰富的数据源和文件格式的读取。
# Spark 针对 Hadoop-MR 做的改进
- 减少了磁盘的 I/O
Spark 将 map 端的中间输出和结果存储在内存中,避免了 reduce 端在拉取 map 端数据的时候造成大量的磁盘 I/O;并且 Spark 将应用程序上传的资源文件缓冲到了 Driver 端本地文件服务的内存中,Executor 在执行任务时直接从 Driver 的内存中读取,也节省了一部分磁盘的 I/O。
- 增加了并行度
由于将中间结果写到磁盘与从磁盘读取中间结果属于不同的环节,Hadoop 将它们简单地通过串行执行衔接起来。Spark 把不同的环节抽象为 Stage,允许多个 Stage 既可以串行执行,又可以并行执行。
- 避免重新计算
当某个 Stage 中的一个 Task 失败之后,Spark 会重新对这个 Stage 进行调度,并且会过滤掉已经执行成功的 Task,避免造成重复的计算和资源的浪费。
- 可选的 Shuffle 排序
MR 在 Shuffle 的时候有着固定的排序操作,但是 Spark 却可以根据不用的场景选择在 map 端排序还是在 reduce 端排序。
- 更加灵活的内存管理
Spark 将内|存划分为堆内存储内存、堆内执行内存、堆外存储内存和堆外执行内存。Spark 即提供了执行内存和存储内存之间固定边界的实现,也提供了执行内存和存储内存之间"软"边界的实现。Spark 默认使用第二种实现方式,无论存储或是执行内存,当哪一方的资源不足时,都可以借用另一方的资源,从而最大限度地提高了资源的利用率。
# 2. 运行时组件
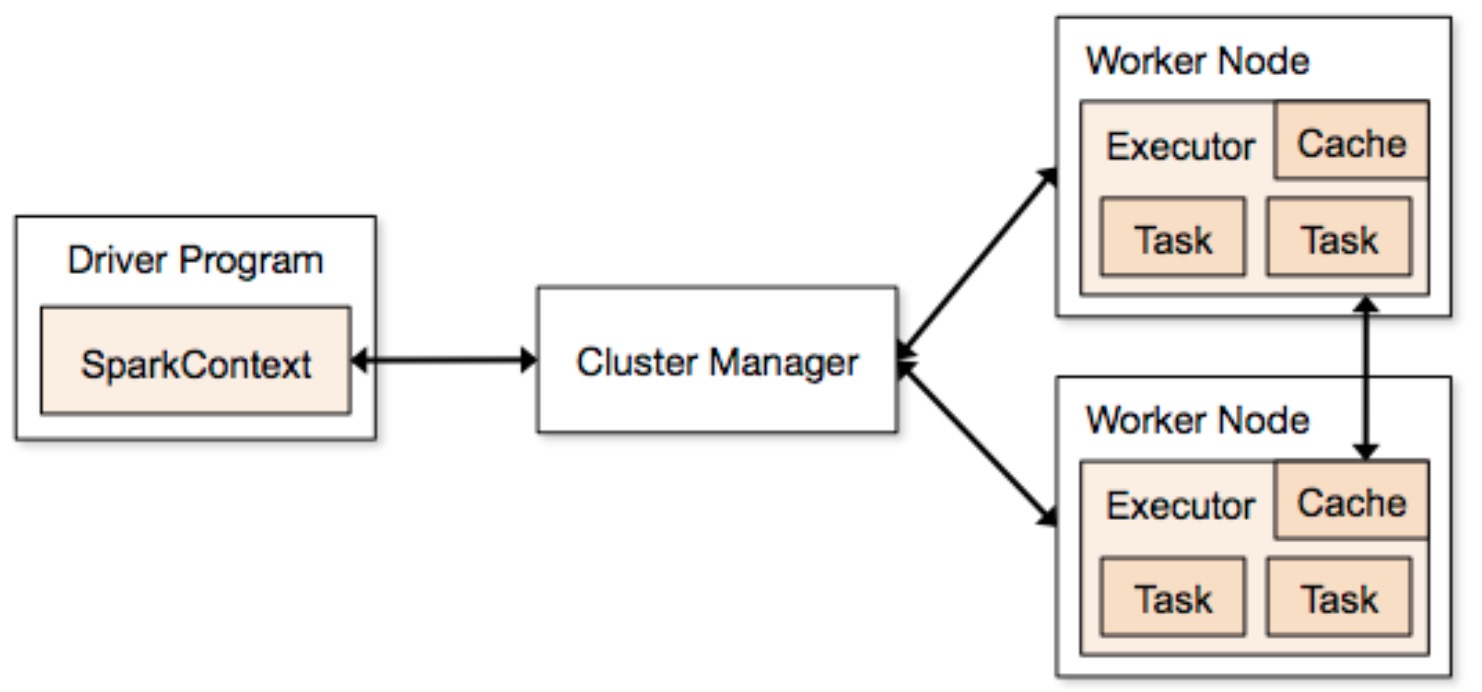
spark-cluster-overview
# Driver
Spark 任务运行调度的核心,负责创建 SparkContext 上下文环境,内部包含 DAGScheduler、TaskScheduler、SchedulerBackend 等重要组件。
负责向 Master 注册当前应用程序并申请计算资源,注册成功后 Master 会为其分配申请的资源。
负责切分任务,并将 Task 分发到不同的 Executor 上执行。
与 Executor 保持通信,任务运行成功或是失败都会向 Driver 进行汇报,当任务执行完成之后,Driver 会关闭 SparkContext。
# Master
Master 是在 local 和 standalone 模式部署下 Spark 集群的一名重要成员,它负责管理整个集群中所有资源的分配,接收 Worker、Driver、Application 的注册,Master 会获得所有已经注册的 Worker 节点的资源信息 (包括:ID、host、port、cpu、memory 等等),用于后续的资源分配。
为了保证集群的高可用,可以同时启动多个 Master,但是这些 Master 只有一个是 Active 状态的,其余的全部为 Standby 状态。Master 实现了 LeaderElectable 接口,当有 Master 发生故障时,会通过 electedLeader() 方法选举新的 Master 领导。
Master 会按照一定的资源调度策略将 Worker 上的资源分配给 Driver 或者 Application。
Master 给 Driver 分配了资源以后,会向 Worker 发送启动 Driver 的命令,Worker 接收到命令后启动 Driver。
Master 根据 Application 申请的资源,选择合适的 Worker 进行资源分配,然后会向 Worker 发送启动 Executor 的命令,Worker 接到命令后启动 Executor。
Master 会和 Worker 保持心跳连接,一是检查 Worker 的存活状态;二是当 Master 出现故障后选举了新的 Master,新的 Master 中并没有保存 Worker 的信息,当 Worker 向 Master 发送心跳的时候,Master 会通知 Worker 重新向新的 Master 进行注册。
# Worker
组成 Spark 集群的成员之一,启动之后会主动向 Master 进行注册,负责向 Master 汇报自身所管理的资源信息,当接到 Master 的命令之后,启动相应的 Driver 或者 Executor。
因为 Worker 启动之后会主动的向 Master 进行注册,因此可以动态的扩展 Worker 节点。
Worker 向 Master 注册成功之后,会以 HEART-BEAT_MILLIS 作为间隔向 Worker 自身发送 SendHeartbeat 消息的定时任务,Worker 接收到 SendHeartbeat 消息后,将向 Master 发送 Heartbeat 消息,Master 也会以 WORKER_TIME-OUT_MS 为时间间隔定时向 Master 自身发送 CheckForWorkerTimeOut 消息,用来检查连接超时的 Worker。
如果 Master 发现了连接超时的 Worker,但是 Worker 的状态并不是 DEAD,此时 Master 会将 Worker 的信息从 idToWorker 中移除,但是 workers 中任然保留着 Worker 的信息,并且会再次向 Worker 发出重新注册的信息。
如果 Master 发现了连接超时的 Worker,并且 Worker 的状态并是 DEAD,那么 Worker 的信息将会从 workers 中被移除。
# Executor
负责执行 Spark 任务的容器,在 Worker 上启动,通过 launchTask() 方法创建 TaskRunner 对象来执行任务,初始化完成后会和 Driver 建立通信,并将任务最后的执行结果发送给 Driver。
# 3. 编程模型
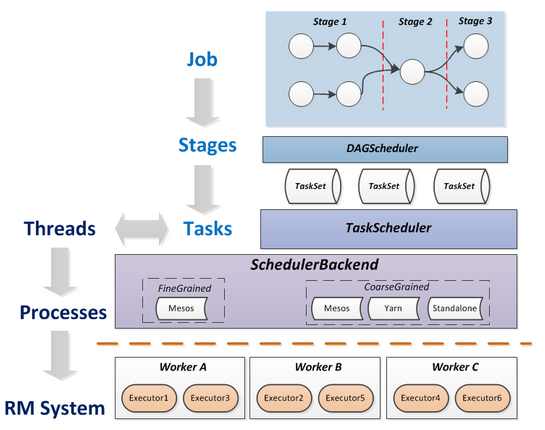
Job 提交到执行过程(来源:https://blog.csdn.net/pelick/article/details/44495611)
# SparkContext
SparkContext 是 Spark 各种功能的主要入口点,表示和 Spark 集群的一种连接,它可以为这个集群创建 RDD、累加器、广播变量等等。
一个 JVM 环境下只能有一个活跃的 SparkContext,你可以通过调用 stop() 方法,停掉活跃的 SparkContext 来创建新的,这种限定在将来可能会被废弃。
重要组成:SparkEnv、SparkUI、LiveListenerBus、SparkStatusTracker、ConsoleProgressBar、JobProgressListener、TaskScheduler、DAGScheduler、HeartBeatReceiver、ContextCleaner、ShutdownHookManager。
# SparkConf
Spark 支持各种各样的配置参数来调整任务的运行,SparkConf 是统一管理这些配置的一个配置类,所有的配置项都由 SparkConf 来进行管理。
所有的配置都保存在一个
ConcurrentHashMap[String,String]中,因此配置 SparkConf 时,无论是 key 还是 value 都是 String 类型的。通过调用 set(key: String, value: String) 方法来给 Spark 设置参数,类似 setMaster() 的方法,内部也是调用了 set() 方法进行参数配置。
在创建 SparkConf 的时候,可以指定一个 Boolean 类型的构造器属性 loadDefaults,当设置为 true 时,会从系统属性中加载以 spark. 字符串为前缀的 key 值,并调用 set() 方法进行赋值。
由于 SparkConf 继承了 Cloneable 特质并实现了 clone 方法,虽然 ConcurrentHashMap 是线程安全的,但是在高并发的情况下,锁机制可能会带来性能上的问题,因此当多个组件共用 SparkConf 的时候,可以通过 clone 方法来创建出多个 SparkConf。
# SparkEnv
SparkEnv 是 Spark 运行时的环境对象,其中包含了 Executor 执行任务时需要的各种对象,例如 RpcEnv、ShuffleManager、BroadcastManager、BlockManager 等,用来管理节点之间的通信、数据的 shuffle、内存空间、数据的计算存储等,所有的 Executor 都持有自己的 SparkEnv 环境对象。此外,在 local 模式下,Driver 会创建 Executor,所以在 Driver 和 CoarseGrainedExecutorBackend 进行中都有 SparkEnv 的存在。
SparkEnv 不是为了提供给外部使用的,有可能会在将来的版本变为私有。
# RDD
RDD 是 Spark 的核心数据结构,全称是弹性分布式数据集( ResilientDistributed Dataset ),其本质是一种分布式的内存抽象,表示一个只读的数据分区(Partition)集合。
一个 RDD 通常只能通过其他的 RDD 转换而创建。RDD 定义了各种丰富的转换操作(如 map、join 和 filter 等),通过这些转换操作,新的 RDD 包含了如何从其他 RDD 衍生所必需的信息,这些信息构成了 RDD 之间的依赖关系( Dependency )。依赖具体分为两种,一种是窄依赖,RDD 之间分区是一一对应的;另一种是宽依赖,下游 RDD 的每个分区与上游 RDD(也称之为父 RDD)的每个分区都有关,是多对多的关系。窄依赖中的所有转换操作可以通过类似管道(Pipeline)的方式全部执行,宽依赖意味着数据需要在不同节点之间 Shuffle 传输。
RDD 计算的时候会通过一个 compute 函数得到每个分区的数据。若 RDD 是通过已有的文件系统构建的,则 compute 函数读取指定文件系统中的数据;如果 RDD 是通过其他 RDD 转换而来的,则 compute 函数执行转换逻辑,将其他 RDD 的数据进行转换。RDD 的操作算子包括两类,一类是 transformation ,用来将 RDD 进行转换,构建 RDD 的依赖关系;另一类称为 action,用来触发 RDD 的计算,得到 RDD 的相关计算结果或将 RDD 保存到文件系统中。
在 Spark 中,RDD 可以创建为对象,通过对象上的各种方法调用来对 RDD 进行转换。经过一系列的 transformation 逻辑之后,就可以调用 action 来触发 RDD 的最终计算。通常来讲,action 包括多种方式,可以是向应用程序返回结果(show、count 和 collect 等),也可以是向存储系统保存数据( saveAsTextFile 等)。在 Spark 中,只有遇到 action,才会真正地执行 RDD 的计算(注:这被称为惰性计算,英文为 Lazy Evqluation ),这样在运行时可以通过管道的方式传输多个转换。
总结而言,基于 RDD 的计算任务可描述为:从稳定的物理存储(如分布式文件系统 HDFS)中加载记录,记录被传入由一组确定性操作构成的 DAG(有向无环图),然后写回稳定存储。RDD 还可以将数据集缓存到内存中,使得在多个操作之间可以很方便地重用数据集。总的来讲,RDD 能够很方便地支持 MapReduce 应用、关系型数据处理、流式数据处理( Stream Processing )和迭代型应用(图计算、机器学习等)。
在容错性方面,基于 RDD 之间的依赖,一个任务流可以描述为 DAG。在实际执行的时候,RDD 通过 Lineage 信息(血缘关系)来完成容错,即使出现数据分区丢失,也可以通过 Lineage 信息重建分区。如果在应用程序中多次使用同一个 RDD,则可以将这个 RDD 缓存起来,该 RDD 只有在第一次计算的时候会根据 Lineage 信息得到分区的数据,在后续其他地方用到这个 RDD 的时候,会直接从缓存处读取而不用再根据 Lineage 信息计算,通过重用达到提升性能的目的。 虽然 RDD 的 Lineage 信息可以天然地实现容错(当 RDD 的某个分区数据计算失败或丢失时,可以通过 Lineage 信息重建),但是对于长时间迭代型应用来说,随着迭代的进行,RDD 与 RDD 之间的 Lineage 信息会越来越长,一旦在后续迭代过程中出错,就需要通过非常长的 Lineage 信息去重建,对性能产生很大的影响。为此,RDD 支持用 checkpoint 机制将数据保存到持久化的存储中,这样就可以切断之前的 Lineage 信息,因为 checkpoint 后的 RDD 不再需要知道它的父 RDD,可以从 checkpoint 处获取数据。
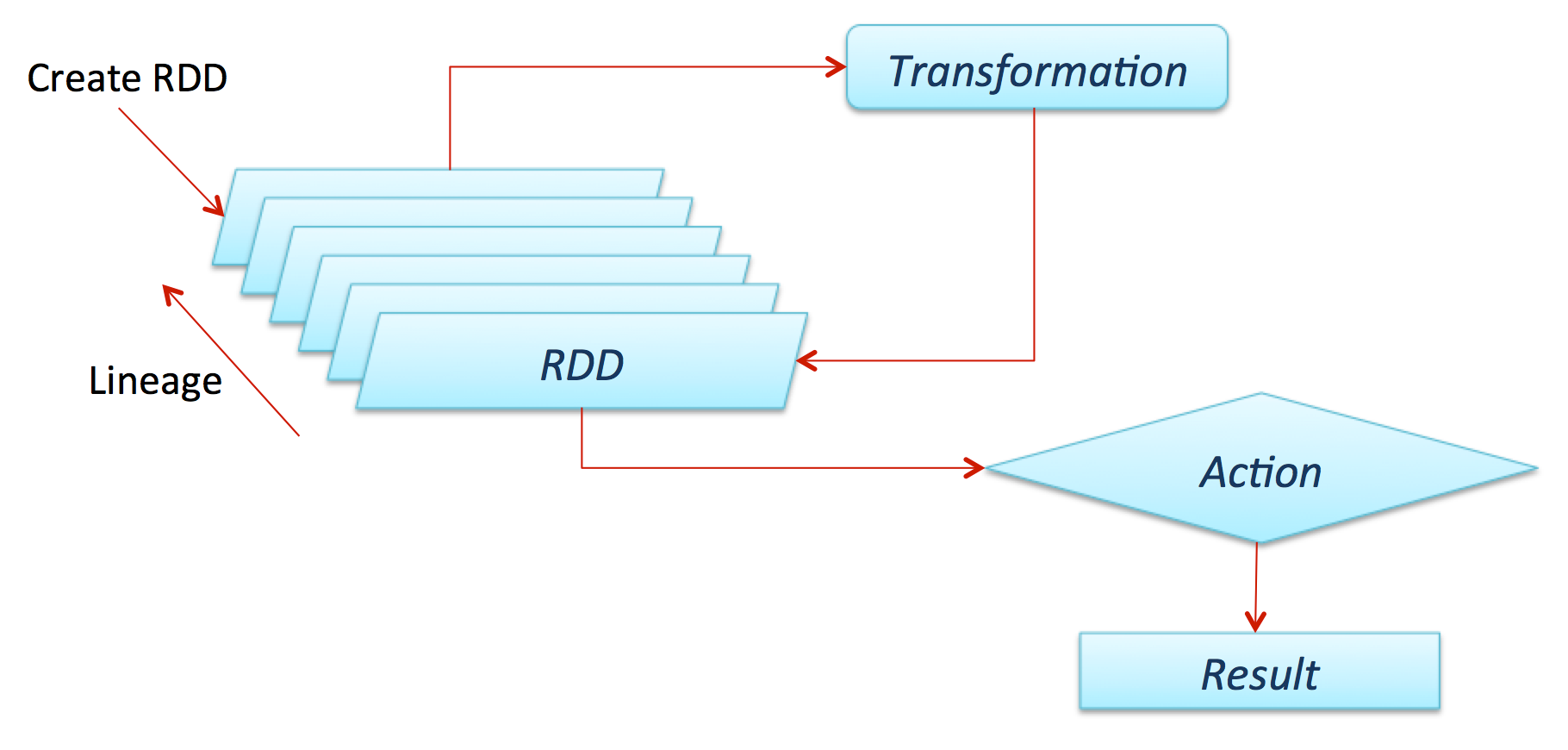
# DAG
有向无环图,在 Spark 中对 RDD 的操作分为两种,一种是 transformation 的,另一种是 action 的,当不断的对 RDD 使用 transformation 算子时,会不断的生成新的 RDD,这些 RDD 之间是存在 ' 血缘关系 ' 的,因此也被称为 lineage,直到触发了 action 动作的算子之后,整个 DAG 图就结束了。DAG 的具体实现在 DAGScheduler 中。
# DAGScheduler
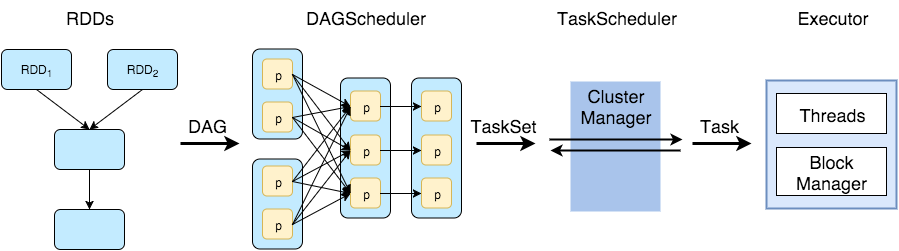
DAGScheduler 是采用 RDD 依赖关系的逻辑计划并将其转换为实际物理计划的组件。 是一个高层次的调度器,负责将 DAG 有向无环图划分成不同的 Stage,划分的依据即为 RDD 之间的宽窄依赖,划分完成之后,构建这些 Stage 之间的父子关系,最后将每个 Stage 按照 Partition 切分成多个 Task,并且以 TaskSet 的形式提交给 TaskScheduler。
# Stage
当 RDD 触发了 action 算子之后,DAGScheduler 会开始分析最终 RDD 形成的依赖关系,逆向往前推导,前一个 RDD 被看做是父 RDD。在 Spark 中 RDD 之间的依赖关系存在两种情况,一种是窄依赖 一种是宽依赖,每当遇到一个宽依赖的时候,便会以此为分界线,划分出一个 Stage。
Stage 分为两种,最后一个 Stage 之前的全部是 ShuffleMapStage,最后一个 Stage 是 ResultStage。
# TaskScheduler
TaskScheduler 是用于向 Worker 上的 Executor 提交任务的组件。
调度程序应用由 spark.scheduler.mode 配置参数设置的调度策略。策略有两种 FAIR(default) / FIFO
TaskScheduler 接收 DAGScheduler 提交过来的 TaskSet 集合,并向 Driver 请求分配任务运行资源,Driver 将可用的 ExecutorBackend 资源发给 TaskScheduler,TaskScheduler 将 Task 合理的分配给所有的 ExecutorBackend,最后会向 ExecutorBackend 发送 launchTask 请求,这时 Executor 会启动 TaskRunner 线程并放到线程池中执行任务。
TaskScheduler 通过 SchedulerBackend 来给 Task 分配资源,并与相应的 Executor 进行通信,让其运行任务。
# Job
用户提交的一个作业,当 RDD 及其 DAG 被提交给 DAGScheduler 调度后,DAGScheduler 会将所有 RDD 中的转换及 Action 动作视为一个 Job。
一个 Job 由一到多个 Task 组成。
# Task
Task 是任务真正的执行者,每个 Stage 会根据 Partition 的数量生成 Task,一个 Stage 中的 Task 最终会包装成一个 TaskSet 传给 TaskScheduler。
每个 Stage 中,一个 Partition 对应一个 Task。
Task 分为两种,一种是 ShuffleMapTask,另一种是 ResultTask。
# 编程模型示意图
# 参考
- 《Spark SQL 内核剖析》
- Apache Spark 源代码演练-Spark 论文阅读笔记以及作业提交和运行 (opens new window)
- spark-job-execution-model (opens new window)

RDD →