专栏原创出处:github-源笔记文件 (opens new window) ,github-源码 (opens new window),欢迎 Star,转载请附上原文出处链接和本声明。
# 1. 什么是 RDD
RDD 是一个弹性的分布式的数据集,是 Spark 中最基础的抽象。它表示了一个可以并行操作的、不可变得、被分区了的元素集合。用户不需要关心底层复杂的抽象处理,直接使用方便的算子处理和计算就可以了。
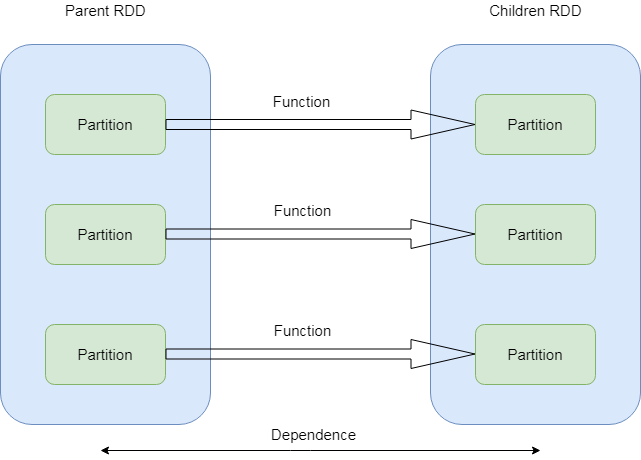
RDD 示意图
# RDD 的五个主要特性
分区列表
Spark RDD 是被分区的,每一个分区都会被一个计算任务 (Task) 处理,分区数决定了并行计千算的数量,RDD 的并行度默认从父 RDD 传给子 RDD。默认情况下,一个 HDFS 上的数据分片就是一个 partiton,RDD 分片数决定了并行计算的力度,可以在创建 RDD 时指定 RDD 分片个数,如果不指定分区数量,当 RDD 从集合创建时,则默认分区数量为该程序所分配到的资源的 CPU 核数 (每个 Core 可以承载 2~4 个 partition),如果是从 HDFS 文件创建,默认为文件的 Block 数。
每一个分区都有一个计算函数
每个分区都会有计算函数, Spark 的 RDD 的计算函数是以分片为基本单位的,每个 RDD 都会实现 compute 函数,对具体的分片进行计算,RDD 中的分片是并行的,所以是分布式并行计算,有一点非常重要,就是由于 RDD 有前后依赖关系,遇到宽依赖关系,如 reduce By Key 等这些操作时划分成 Stage, Stage 内部的操作都是通过 Pipeline 进行的,在具体处理数据时它会通过 Blockmanager 来获取相关的数据,因为具体的 split 要从外界读数据,也要把具体的计算结果写入外界,所以用了一个管理器,具体的 split 都会映射成 BlockManager 的 Block,而体的 splt 会被函数处理,函数处理的具体形式是以任务的形式进行的。
RDD 之间具有依赖关系
由于 RDD 每次转换都会生成新的 RDD,所以 RDD 会形成类似流水线一样的前后依赖关系,当然宽依赖就不类似于流水线了,宽依赖后面的 RDD 具体的数据分片会依赖前面所有的 RDD 的所有数据分片,这个时候数据分片就不进行内存中的 Pipeline,一般都是跨机器的,因为有前后的依赖关系,所以当有分区的数据丢失时, Spark 会通过依赖关系进行重新计算,从而计算出丢失的数据,而不是对 RDD 所有的分区进行重新计算。RDD 之间的依赖有两种:窄依赖 ( Narrow Dependency) 和宽依赖 ( Wide Dependency)。RDD 是 Spark 的核心数据结构,通过 RDD 的依赖关系形成调度关系。通过对 RDD 的操作形成整个 Spark 程序。
key-value 数据类型的 RDD 分区器、控制分区策略和分区数
每个 key-value 形式的 RDD 都有 Partitioner 属性,它决定了 RDD 如何分区。当然,Partiton 的个数还决定了每个 Sage 的 Task 个数。RDD 的分片函数可以分区 ( Partitioner),可传入相关的参数,如 Hash Partitioner 和 Range Partitioner,它本身针对 key- value 的形式,如果不是 key-ale 的形式它就不会有具体的 Partitioner, Partitioner 本身决定了下一步会产生多少并行的分片,同时它本身也决定了当前并行 ( Parallelize) Shuffle 输出的并行数据,从而使 Spak 具有能够控制数据在不同结点上分区的特性,用户可以自定义分区策略,如 Hash 分区等。 spark 提供了 partition By 运算符,能通过集群对 RDD 进行数据再分配来创建一个新的 RDD。
每个分区都有一个优先位置列表
优先位置列表会存储每个 Partition 的优先位置,对于一个 HDFS 文件来说,就是每个 Partition 块的位置。观察运行 Spark 集群的控制台就会发现, Spark 在具体计算、具体分片以前,它已经清楚地知道任务发生在哪个结点上,也就是说任务本身是计算层面的、代码层面的,代码发生运算之前它就已经知道它要运算的数据在什么地方,有具体结点的信息。这就符合大数据中数据不动代码动的原则。数据不动代码动的最高境界是数据就在当前结点的内存中。这时候有可能是 Memory 级别或 Tachyon 级别的, Spark 本身在进行任务调度时会尽可能地将任务分配到处理数据的数据块所在的具体位置。据 Spark 的 RDD。 Scala 源代码函数 getParferredlocations 可知,每次计算都符合完美的数据本地性。
# 初始化 RDD
并行集合的方式:
val data = Array(1, 2, 3, 4, 5)
val distData = sc.parallelize(data)
引用外部存储系统的数据集 (text、HDFS、Hbase 等):
val distFile = sc.textFile("data.txt")
如果使用本地文件系统初始化 RDD,需要保证每个工作的节点上在相同的路径下都具有该文件。
所有通过文件初始化 RDD 的方法,都支持使用通配符和压缩文件。
初始化 RDD 的时候可以通过第二个参数指定分区数,但是分区数不能少于文件块数,例如 HDFS 中文件默认 128M 分割一个文件块,一个 512M 的文件会有 4 个文件块,因此指定分区的时候,分区数必须 >=4。
# 操作 RDD
转换类型的操作:例如 map 算子,它没有对 RDD 进行真正的计算,只是记录下了这些对 RDD 的转换操作,它会生成一个新的 RDD,这两个 RDD 之间具有依赖关系。
常见的转换类型算子:map、filter、flatMap、mapPartitions、sample、union、distinct、groupByKey、reduceByKey、sortByKey、join、repartition。
动作类型的操作:例如 collect 算子,当动作类型操作触发之后,才会从首个 RDD 开始,根据依赖关系进行计算,最终将结果返回给 Client。
常见的动作类型算子:reduce、collect、count、first、take、saveAsTextFile、countByKey、foreach。
# 闭包问题
最简单的理解就是在 RDD 的算子中使用了外部 (Driver 端) 定义的变量。
var counter = 0
var rdd = sc.parallelize(data)
// 不能这样使用,该出在 foreach 算子的函数内引用了 Driver 端定义的 counter 变量,即闭包操作。
rdd.foreach(x => counter += x)
println("Counter value: " + counter) // Counter value: 0
在外部定义了一个变量 counter 是属于 Driver 端的,在 RDD 调用 foreach 的时候使用了该变量,由于 RDD 的分区分布在不同的节点上,其实在 foreach 中使用的 counter 只是一个广播出去的副本,累加的时候也是对该副本的值进行累加,Driver 端定义的 counter 的真实值并没有发生改变,最终输出的 counter 的值依然是 0。
可以使用 Accumulator 累加器来避免此类问题,详细介绍请参考《共享变量》部分。
# 2. Stage 划分
# 宽依赖与窄依赖
RDD 每经过一次转换操作都会生成一个新的 RDD,它们之间存在着依赖关系,这种依赖关系被划分成了两种,即窄依赖和宽依赖。
窄依赖:父 RDD 中每个分区的数据只由子 RDD 的一个分区使用。
宽依赖:父 RDD 中一个分区的数据被多个子 RDD 的分区使用。
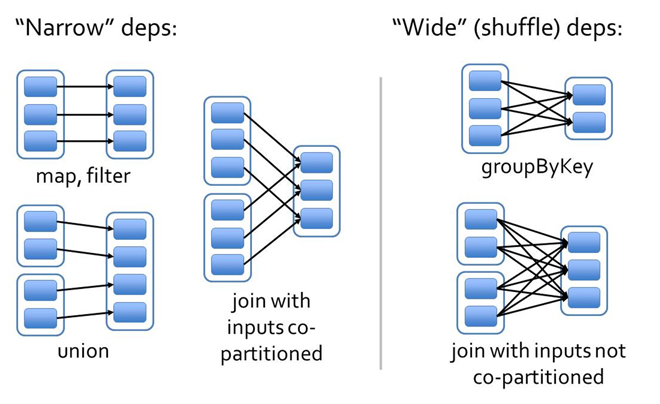
宽窄依赖示意图
# 如何划分 Stage
当 RDD 触发了 action 算子之后,DAGScheduler 会开始分析最终 RDD 形成的依赖关系,逆向往前推导,前一个 RDD 被看做是父 RDD。每当遇到一个宽依赖的时候,便会以此为分界线,划分出一个 Stage。
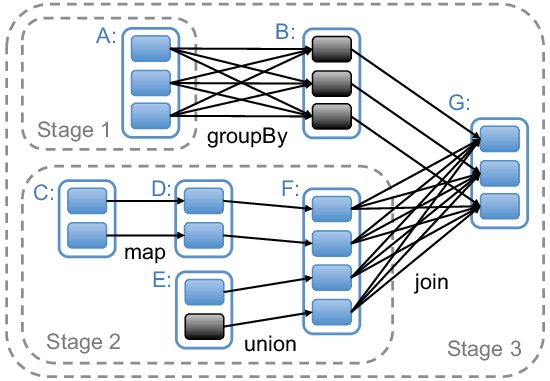
stage 划分
# 3. RDD 的缓存
当一个 RDD 需要被重复使用时,或者当任务失败重新计算的时候,这时如果将 RDD 缓存起来,就可以避免重新计算,保证程序运行的性能。
RDD 的缓存有三种方式:cache、persist、checkPoint。
cache 方法不是在被调用的时候立即进行缓存,而是当触发了 action 类型的算子之后,才会进行缓存。
Spark 会监控每个节点上的缓存情况,会丢弃掉最少使用的旧的缓存数据,也可以手动释放缓存数据,使用 RDD.unpersist 方法。
指定缓存级别参考
org.apache.spark.storage.StorageLevel类定义
# cache 和 persist 的区别
其实 cache 底层实际调用的就是 persist 方法,只是缓存的级别默认是 MEMORY_ONLY,而 persist 方法可以指定其他的缓存级别。
# cache 和 checkPoint 的区别
checkPoint 是将数据缓存到本地或者 HDFS 文件存储系统中,当某个节点的 executor 宕机了之后,缓存的数据不会丢失,而通过 cache 缓存的数据就会丢掉。
checkPoint 的时候会把 job 从开始重新再计算一遍,因此在 checkPoint 之前最好先进行一步 cache 操作,cache 不需要重新计算,这样可以节省计算的时间。
# persist 和 checkPoint 的区别
persist 也可以选择将数据缓存到磁盘当中,但是它交给 blockManager 管理的,一旦程序运行结束,blockManager 也会被停止,这时候缓存的数据就会被释放掉。而 checkPoint 持久化的数据并不会被释放,是一直存在的,可以被其它的程序所使用。
