专栏原创出处:github-源笔记文件 (opens new window) ,github-源码 (opens new window),欢迎 Star,转载请附上原文出处链接和本声明。
# 1. 什么是 Shuffle
当一个父 RDD 分区的数据分散到了多个子 RDD 的分区中时,这时会产生 Shuffle,即宽依赖之间会有 Shuffle。
Reduce Task 去拉取 Map Task 数据的时候会产生大量的网络、磁盘 IO、内存的消耗,Shuffle 性能的高低对整体任务的性能影响很大。
Shuffle 通常分为两个阶段,Map 阶段数据的准备及划分,Reduce 阶段数据的拉取。Map 端的 Shuffle 通常被称作 Shuffle Write,Reduce 端的 Shuffle 通常被称作 Shuffle Read。
# 2. Shuffle 管理器的发展史
Spark 1.2 之前 Shuffle 使用的计算引擎是 HashShuffleManager,这种方式虽然快速,但是会产生大量的文件,如果有 M 个 Mapper,N 个 Reducer 就会产生 M * N 个文件,如果 Mapper 和 Reducer 的数量很庞大将会带来性能上的影响。
Spark 1.2 之后引入了 SortShuffleManager,这种方式 Reduce 端需要读取的文件更少,因为 Map 端的每个 Task 最后会将临时文件合并成一个文件,并且会对 Map 端的数据进行排序,并生成记录数据位置的索引文件,Reducer 可以通过索引找到自己要拉取的数据,它也是 Spark 默认使用的 Shuffle 管理器。
Spark 2.0 之后移除了 HashShuffleManager,目前 ShuffleManager 只有 SortShuffleManager 这一个实现类。
# 3. SortShuffleManager 解析
SortShuffleManager 有两种运行机制,一种是普通机制,另一种是 bypass 机制。
# 3.1.普通机制解析
Shuffle Write 阶段会先将数据写入内存数据结构中,如果是聚合类型的算子 (reduceByKey),采用 Map 数据结构,先用 Map 进行预聚合处理,再写入内存中;如果是普通的 shuffle 算子的话 (join),采用 Array 数据结构,直接写入内存。
当内存达到阈值的时候,会将这些内存中的数据进行排序,然后分批次写入磁盘文件 (默认 1W/批),这里并不会直接写入磁盘,会先写入内存缓冲流中,当缓冲流满溢之后,写入磁盘文件。
最后会将每个 Task 写出的文件进行合并,最终生成一份数据文件和一份索引文件,索引文件记录了 Shuffle Read 阶段每个 Task 要读取的数据在文件中对应的开始和结束位置。
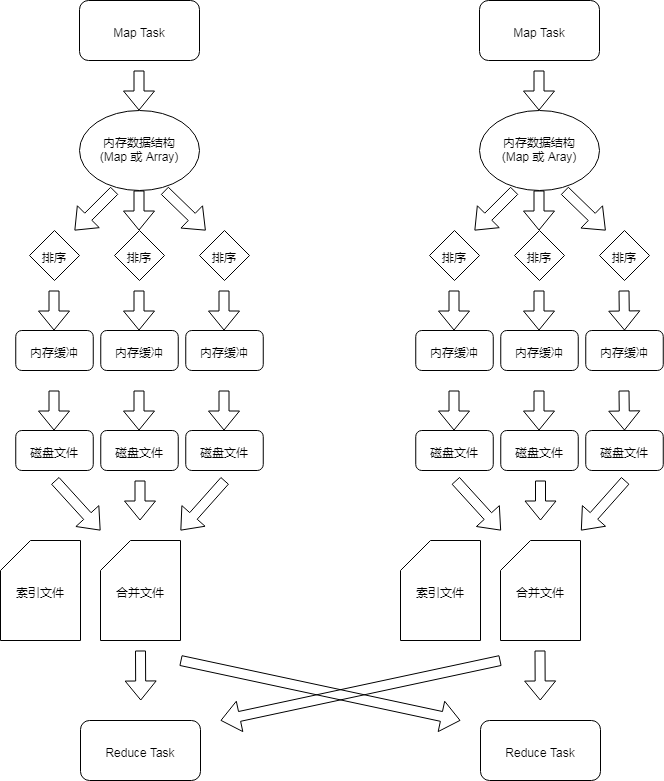
普通机制
# 3.2.bypass 机制解析
Shuffle Write 阶段会对每个 Task 数据的 key 进行 hash,相同 hash 的 key 会被写入同一个内存缓冲区,缓冲区满溢后会写到磁盘文件中。
最后会将每个 Task 写出的磁盘文件进行合并,并创建索引文件 (与普通机制下的索引文件作用相同)。

bypass 机制
# 3.3.bypass 机制开启条件
shuffle read task 的数量小于等于 spark.shuffle.sort.bypassMergeThreshold 参数设置的阈值的时候,默认是 200。
触发 shuffle 的算子不能是聚合类算子,比如 reduceByKey(在 Map 端对每一个 Task 的 key 会先进行一次预聚合处理)。
# 4. SortShuffleManager 两种机制的区别
在将数据写入内存缓冲区的时候,普通机制要先将数据写入 Map 或者 Array 的内存数据结构中,而 bypass 机制是根据 key 的 hash 值直接写入内存缓冲区中。
bypass 机制在写入内存缓冲区之前没有对数据的排序操作,因此在 reduce task 比较少的情况下,开启 bypass 机制,不需要对数据排序,节省运算性能。
