专栏原创出处:github-源笔记文件 (opens new window) ,github-源码 (opens new window),欢迎 Star,转载请附上原文出处链接和本声明。
# 1.部署模式
# 1.1.本地部署模式
local 部署模式只有 Driver,没有 Master 和 Worker,执行任务的 Executor 与 Driver 在同一个 JVM 进程内,此类模式主要用于代码调试和跟踪,不具备高可用性、可扩展性,所以不适用于生产环境。
设置 master 的几种方式:
local 只运行一个 Worker 线程。
local[N] 运行 N 个 Worker 线程。
local[*] 运行 CPU 最大核数相同数量的 Worker 线程。
local[N,M] 运行 N 个 Worker 线程,失败的任务进行 M-1 次重试。
local[*,M] 运行 CPU 最大核数相同数量的 Worker 线程,失败的任务进行 M-1 次重试。
# 1.2.Standalone 部署模式
此模式具备高可用性并且支持分布式部署,所以可用于实际的生产环境。
使用此模式首先要有一个 Spark 集群环境,也就是要启动一个 Master 和 若干个 Worker 节点。可以通过 SPARK_HOME/sbin/ 目录下的启动脚本,启动相应的组件。
CoarseGrainedExecutorBackend 是执行任务的进程名称,当你提交了任务之后,可以看到该进程的运行,它其实就是 Executor。
通过 --master spark://HOST:PORT 来使用 Standalone 模式提交任务。
使用 spark-shell 提交任务的时候,Driver 位于 Master 端。
使用 spark-submit 或者在 Eclips、Idea 开发平台该上提交任务的时候,Driver 位于 Client 端。
# 1.3.On-Yarn 部署模式
将 Spark 任务的整体运作交给 Yarn 集群管理,不需要启动 Master 和 Worker,所有的资源调度和执行任务容器的创建都由 Yarn 来完成。
通过 --master yarn 来指定 Spark On Yarn 的部署模式。
该模式又有两种子模式,通过 --deploy-mode cluster 或者 --deploy-mode client 来指定,cluster 和 client 两种模式唯一的区别就是 Driver 端运行的位置不一样。
# 2. 任务提交流程
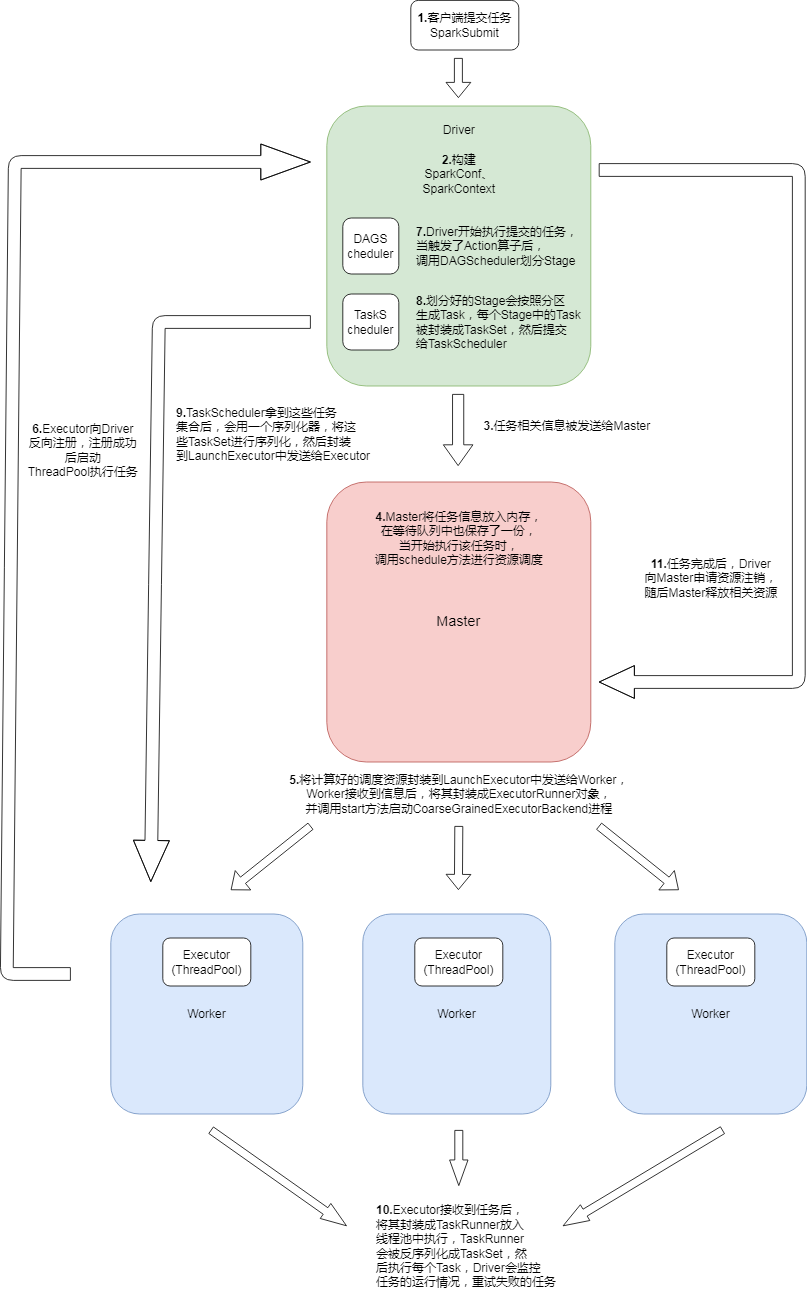
任务提交流程
# 2.1.Standalone 模式
用户提交任务后通过 SparkSubmit 类的 main 方法匹配到 SUBMIT 模式,然后调用 submit 方法,通过反射获取到主类对象并执行主类对象的 main 方法。
然后构建 SparkConf 和 SparkContext,其中 SparkContext 中又初始化了 SparkEnv、DAGScheduler、TaskScheduler 这三个对象。
任务的相关信息被封装到了 ApplicationDescription 之后,由 StandaloneAppClient 携带发送给 Master。
Master 接收到任务信息后将其放入内存,并在 waitingApps 队列中也保存一份,当开始执行该任务时,调用 schedule 方法进行资源调度。
将计算好的调度资源封装到 LaunchExecutor 中发送给 Worker,Worker 接收到调度信息后,将其封装成一个 ExecutorRunner 对象并调用 start 方法启动 CoarseGrainedExecutorBackend 进程。
Executor 启动后向 Driver 反向注册,注册成功后会创建一个线程池 ThreadPool 来执行任务。
Executor 注册完成后,Driver 开始执行我们提交的任务,当执行了 action 算子之后,这时就触发了一个 job,然后调用 DAGScheduler 进行 Stage 划分。
划分好的 Stage 会按照分区生成 Task,这些 Task 会被封装成 TaskSet 提交给 TaskScheduler。
TaskScheduler 拿到这些任务集合后,会用一个序列化器,将这些 TaskSet 进行序列化,然后封装到 LaunchExecutor 中发送给 Executor。
Executor 接收到这些任务后,再将它们封装成 TaskRunner,然后丢到线程池中执行。
TaskRunner 会被反序列化成 TaskSet,然后执行每个 Task 中的任务,也就是对 RDD 的每个分区上执行对应的算子。
Driver 负责监控任务的运行情况,重试失败的任务。任务运行完成之后 Driver 会向 Master 申请注销,然后 Master 释放相关资源。
# 2.2.On-Yarn 模式
与 Standalone 模式运行的整体流程大体一致,只是所有的功能都统一交给了 Yarn 来管理。
On-Yarn 模式多了一个组件就是 Application Master(简称 AM),AM 负责资源的申请以及任务运行情况的监控。客户端提交了任务后,ResourceManager(简称 RM) 会首先创建一个容器启动 AM,AM 获取到 Driver 需要的资源信息之后向 RM 申请资源,RM 找到合适的 NodeManager(简称 NM) 后在上面创建 Container 容器,并将这些容器信息返回给 AM,AM 与这些容器对应的 NM 建立通信,并在容器里启动 Executor。
RM 主要负责监控集群中所有组件的运行情况以及向 AM 分配资源、创建 Container 容器。
RM 和 AM 整体相当于 Master,NM 相当于 Worker,RM 会在 NM 上创建容器 Container 来启动相关的组件。
# 2.3.Yarn-Client 和 Yarn-Cluster 的区别
Yarn-Client 和 Yarn-Cluster 模式的唯一区别就是 Driver 启动的位置不同,Client 模式下 Driver 启动在用户提交任务的客户端上,用户可以看到 Driver 输出的日志,程序如果中断,整体任务就断掉了;Cluster 模式下,Driver 运行在 AM 中,客户端看不到 Driver 输出的日志,并且客户端提交完任务之后可以强行中断掉,并不会影响任务的正常运行。
Yarn-Cluster 更适合用于生产环境,因为 Client 模式下,Driver 运行在客户端,当 Driver 和 Executor 之间有大量通信的时候,会造成网络 I/O 的压力,并且如果客户端提交了许多 Spark 任务的话,客户端启动的大量 Driver 程序对客户端的资源也会造成一定的压力。``
