专栏原创出处:github-源笔记文件 (opens new window) ,github-源码 (opens new window),欢迎 Star,转载请附上原文出处链接和本声明。
本节内容对应官方文档 (opens new window)
# 1 数据类型以及序列化
Apache Flink 以其独特的方式来处理数据类型以及序列化,这种方式包括它自身的类型描述符、泛型类型提取以及类型序列化框架。
本文档描述了它们背后的概念和基本原理。
# 2 类型处理
Flink 会尽力推断有关数据类型的大量信息,这些数据会在分布式计算期间被网络交换或存储。
可以把它想象成一个推断表结构的数据库。
在大多数情况下,Flink 可以依赖自身透明的推断出所有需要的类型信息。
掌握这些类型信息可以帮助 Flink 实现很多意想不到的特性:
对于使用 POJOs 类型的数据,可以通过指定字段名(比如 dataSet.keyBy("username") )进行 grouping 、joining、aggregating 操作。
类型信息可以帮助 Flink 在运行前做一些拼写错误以及类型兼容方面的检查,而不是等到运行时才暴露这些问题。Flink 对数据类型了解的越多,序列化和数据布局方案就越好。
这对 Flink 中的内存使用范式尤为重要(可以尽可能处理堆上或者堆外的序列化数据并且使序列化操作很廉价)。最后,它还使用户在大多数情况下免于担心序列化框架以及类型注册。
通常在应用运行之前的阶段 (pre-flight phase),需要数据的类型信息 - 也就是在程序对 DataStream 或者 DataSet 的操作调用之后,在 execute()、print()、count()、collect() 调用之前。
# 3 最常见问题
用户需要与 Flink 数据类型处理进行交互的最常见问题是:
注册子类型 如果函数签名只包含超类型,但它们实际上在执行期间使用那些类型的子类型,则使 Flink 感知这些子类型可能会大大提高性能。
可以为每一个子类型调用 StreamExecutionEnvironment 或者 ExecutionEnvironment 的 .registerType(clazz) 方法。注册自定义序列化器: 当 Flink 无法通过自身处理类型时会回退到 Kryo 进行处理。
并非所有的类型都可以被 Kryo (或者 Flink ) 处理。
例如谷歌的 Guava 集合类型默认情况下是没办法很好处理的。
解决方案是为这些引起问题的类型注册额外的序列化器。
调用 StreamExecutionEnvironment 或者 ExecutionEnvironment 的 .getConfig().addDefaultKryoSerializer(clazz, serializer) 方法注册 Kryo 序列化器。添加类型提示 Flink 用尽一切手段也无法推断出泛型类型,用户需要提供类型提示。
手动创建 TypeInformation: 这可能是某些 API 调用所必需的,因为 Java 的泛型类型擦除会导致 Flink 无法推断出数据类型。
# 4 TypeInformation 类
类 TypeInformation 是所有类型描述符的基类。
该类表示类型的基本属性,并且可以生成序列化器,在一些特殊情况下可以生成类型的比较器。
(请注意,Flink 中的比较器不仅仅是定义顺序 - 它们是处理键的基础工具)
Flink 内部对类型做了如下区分:
基础类型:所有的 Java 主类型(primitive)以及他们的包装类,再加上 void、String、Date、BigDecimal 以及 BigInteger。
主类型数组(primitive array)以及对象数组
复合类型
- Flink 中的 Java 元组 (Tuples) (元组是 Flink Java API 的一部分):最多支持 25 个字段,null 是不支持的。
- Scala 中的 case classes (包括 Scala 元组):null 是不支持的。
- Row:具有任意数量字段的元组并且支持 null 字段。。
- POJOs: 遵循某种类似 bean 模式的类。
辅助类型 (Option、Either、Lists、Maps 等)
泛型类型:这些不是由 Flink 本身序列化的,而是由 Kryo 序列化的。
介于 TypeInformation子类较多,仅展示基础类型、组合类型、对象数组 与 TypeInformation 继承关系,实际情况参考源码分析
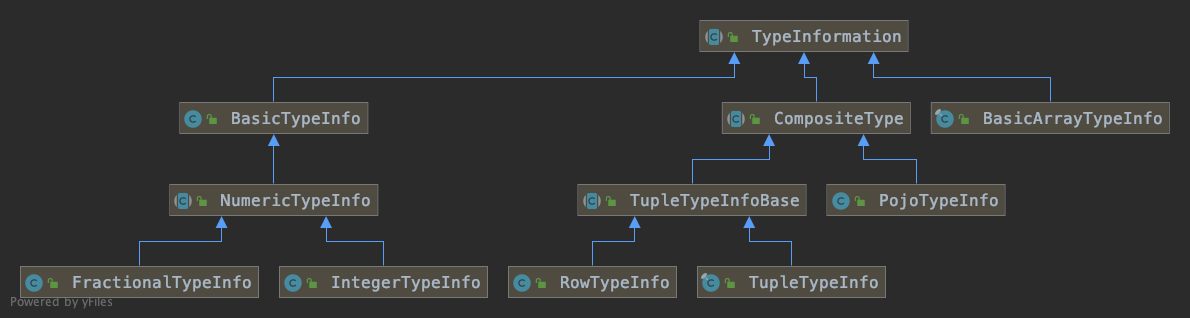
POJOs 是特别有趣的,因为他们支持复杂类型的创建以及在键的定义中直接使用字段名: dataSet.join(another).where("name").equalTo("personName") 它们对运行时也是透明的,并且可以由 Flink 非常高效地处理。
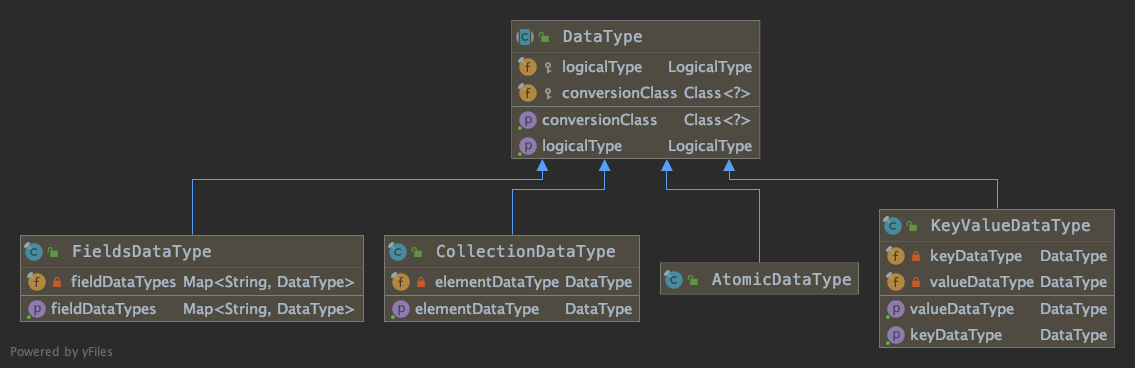
# 5 DataType 类
描述 Table SQL API 中数据类型。此类的实例可用于声明操作的输入和/或输出类型。
DataType 类有两个职责:
- 声明逻辑类型
LogicalType logicalType - 运行时逻辑转换类
Class<?> conversionClass,可以为空。
为空时,使用每个逻辑类型实际支持输入输出支持类型 e.g.LogicalType#supportsInputConversion
logicalType独立于任何运行时逻辑转换类形式,并且描述接近 SQL 标准的术语
例如 TimestampType extends LogicalType ,TimestampType 支持 java.sql.Timestamp、java.time.LocalDateTime 两种类型,
如果不指定具体运行时处理类,默认按 java.time.LocalDateTime 进行数据转换操作。
val time = DataTypes.TIME()
info(s"${time.getLogicalType}") // TIME(0)
info(s"${time.getConversionClass}") // class java.time.LocalTime
请参阅link org.apache.flink.table.types.logical.LogicalType和其子类,以获取有关可用逻辑类型及其属性的更多信息。
参见 DataTypes 以获取支持的数据类型和此类实例的列表
# 创建 TypeInformation 或者 TypeSerializer
要为类型创建 TypeInformation 对象,需要使用特定于语言的方法:
# 在 Scala 中
org.apache.flink.api.scala.typeutils.Types 提供 scala 相关类型的方法
Flink 使用在编译时运行的宏捕获所有泛型类型信息。
// 注意:这个导入是为了访问 'createTypeInformation' 的宏函数
// implicit def createTypeInformation[T]: TypeInformation[T] = macro TypeUtils.createTypeInfo[T]
import org.apache.flink.streaming.api.scala._
object TypeInformationApp extends MainApp {
// 获取 TypeInformation
val appleType1 = TypeInformation.of(classOf[Apple])
val appleType2 = createTypeInformation[Apple]
// case class 获取 TypeInformation
val appleType = Types.CASE_CLASS[Apple].asInstanceOf[CaseClassTypeInfo[Apple]]
info(s"${appleType.isCaseClass()}") // true
// 泛型推导
val tuple2 = Types.TUPLE[(String, Int)]
info(s"${tuple2.getGenericParameters}") // {T1=String, T2=Integer}
// 泛型推导
val boxType = Types.CASE_CLASS[Box[Apple]].asInstanceOf[CaseClassTypeInfo[Box[Apple]]]
info(s"${boxType.getGenericParameters()}") // {T1=Apple(color: String, size: Integer)}
// 字段类型获取
val fieldTypes = (boxType.fieldNames, boxType.fieldNames.map(boxType.getTypeAt))
info(s"$fieldTypes")
// (
// List(content, maxWeight),
// List(ObjectArrayTypeInfo<Apple(color: String, weight: Integer)>, Integer)
// )
}
/**
* 苹果
*
* @param color 颜色
* @param weight 重量
*/
case class Apple(color: String, weight: Int)
/** 箱子
*
* @param content 内容,e.g. 内容是一箱子苹果
* @param maxWeight 最大重量
* @tparam T 箱子内内容描述
*/
case class Box[T](content: Array[T], maxWeight: Int)
# 6 Scala API 中的类型信息
implicit def createTypeInformation[T]: TypeInformation[T] = macro TypeUtils.createTypeInfo[T]
Scala 拥有精细的运行时类型信息概念 type manifests 以及 class tags。类型和方法通常可以访问他们泛型参数的类型 - 因此,Scala 程序不像 Java 程序那样需要面对类型擦除的问题。
此外,Scala 允许通过 Scala 宏在 Scala 编译器中运行自定义代码 - 这意味着无论何时编译使用 Flink Scala API 编写的 Scala 程序,都会执行一些 Flink 代码。
我们在编译期间使用宏来查看所有用户自定义函数的参数类型和返回类型 - 这是所有类型信息都完全可用的时间点。 在宏中,我们为函数的返回类型(或参数类型)创建了 TypeInformation,并使其成为操作的一部分。
# 泛型方法
考虑下面的代码:
def selectFirst[T](input: DataSet[(T, _)]) : DataSet[T] = {
input.map { v => v._1 }
}
val data : DataSet[(String, Long) = ...
val result = selectFirst(data)
对于上面这样的泛型方法,函数的参数类型以及返回类型可能每一次调用都是不同的并且没有办法在方法定义的时候被感知到。 上面的代码将导致没有足够的隐式转换可用错误。
在这种情况下,类型信息必须在调用时间点生成并将其传递给方法。Scala 为此提供了隐式转换。
下面的代码告诉 Scala 将 T 的类型信息带入函数中。类型信息会在方法被调用的时间生成,而不是 方法定义的时候。
def selectFirst[T : TypeInformation](input: DataSet[(T, _)]) : DataSet[T] = {
input.map { v => v._1 }
}
# 7 Java API 中的类型信息
Java 会擦除泛型类型信息。Flink 使用 Java 预留的少量位(主要是函数签名以及子类信息)通过反射尽可能多的重新构造类型信息。 对于依赖输入类型来确定函数返回类型的情况,此逻辑还包含一些简单类型推断:
public class AppendOne<T> implements MapFunction<T, Tuple2<T, Long>> {
public Tuple2<T, Long> map(T value) {
return new Tuple2<T, Long>(value, 1L);
}
}
在某些情况下,Flink 无法重建所有泛型类型信息。 在这种情况下,用户必须通过类型提示来解决问题。
# Java API 中的类型提示
在 Flink 无法重建被擦除的泛型类型信息的情况下,Java API 需要提供所谓的类型提示。 类型提示告诉系统 DateStream 或者 DateSet 产生的类型:
DataSet<SomeType> result = dataSet
.map(new MyGenericNonInferrableFunction<Long, SomeType>())
.returns(SomeType.class);
在上面情况下 returns 表达通过 Class 类型指出产生的类型。通过下面方式支持类型提示:
对于非参数化的类型(没有泛型)的 Class 类型 以 returns(new TypeHint<Tuple2<Integer, SomeType>>(){}) 方式进行类型提示。 TypeHint 类可以捕获泛型的类型信息并且保存到执行期间(通过匿名子类)。
# POJO 类型的序列化
PojoTypeInfo 为 POJO 中的所有字段创建序列化器。Flink 标准类型如 int、long、String 等由 Flink 序列化器处理。 对于所有其他类型,我们回退到 Kryo。
对于 Kryo 不能处理的类型,你可以要求 PojoTypeInfo 使用 Avro 对 POJO 进行序列化。 需要通过下面的代码开启。
final ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
env.getConfig().enableForceAvro();
请注意,Flink 会使用 Avro 序列化器自动序列化 Avro 生成的 POJO。
通过下面设置可以让你的整个 POJO 类型被 Kryo 序列化器处理。
final ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
env.getConfig().enableForceKryo();
如果 Kryo 不能序列化你的 POJO,可以通过下面的代码添加自定义的序列化器
env.getConfig().addDefaultKryoSerializer(Class<?> type, Class<? extends Serializer<?>> serializerClass)
# 8 禁止回退到 Kryo
对于泛型信息,程序可能希望在一些情况下显示的避免使用 Kryo。最常见的场景是,用户想要确保所有的类型都可以通过 Flink 自身 或者用户自定义的序列化器高效的进行序列化操作。
下面的设置将引起通过 Kryo 的数据类型抛出异常:
env.getConfig().disableGenericTypes();
# 9 使用工厂方法定义类型信息
类型信息工厂允许将用户定义的类型信息插入 Flink 类型系统。 你可以通过实现 org.apache.flink.api.common.typeinfo.TypeInfoFactory 来返回自定义的类型信息工厂。 如果相应的类型已指定了 @org.apache.flink.api.common.typeinfo.TypeInfo 注解,则在类型提取阶段会调用 TypeInfo 注解指定的 类型信息工厂。
类型信息工厂可以在 Java 和 Scala API 中使用。
在类型的层次结构中,在向上遍历时将选择最近的工厂,但是内置工厂具有最高优先级。 工厂的优先级也高于 Flink 的内置类型,因此你应该知道自己在做什么。
以下示例说明如何使用 Java 中的工厂注释为自定义类型 MyTuple 提供自定义类型信息。
带注解的自定义类型:
@TypeInfo(MyTupleTypeInfoFactory.class)
public class MyTuple<T0, T1> {
public T0 myfield0;
public T1 myfield1;
}
支持自定义类型信息的工厂:
public class MyTupleTypeInfoFactory extends TypeInfoFactory<MyTuple> {
@Override
public TypeInformation<MyTuple> createTypeInfo(Type t, Map<String, TypeInformation<?>> genericParameters) {
return new MyTupleTypeInfo(genericParameters.get("T0"), genericParameters.get("T1"));
}
}
方法 createTypeInfo(Type, Map<String, TypeInformation<?>>) 为工厂所对应的类型创建类型信息。 参数提供有关类型本身的额外信息以及类型的泛型类型参数。
如果你的类型包含可能需要从 Flink 函数的输入类型派生的泛型参数, 请确保还实现了 org.apache.flink.api.common.typeinfo.TypeInformation#getGenericParameters, 以便将泛型参数与类型信息进行双向映射。
← 编程模型 开发前准备与模拟数据集介绍 →