专栏原创出处:github-源笔记文件 (opens new window) ,github-源码 (opens new window),欢迎 Star,转载请附上原文出处链接和本声明。
Java 并发编程专栏系列笔记,系统性学习可访问个人复盘笔记-技术博客 Java 并发编程 (opens new window)
# volatile 的特性
定义:
java 编程语言允许线程访问共享变量,为了确保共享变量能被准确和一致的更新,线程应该确保通过排他锁单独获得这个变量。Java 语言提供了 volatile,在某些情况下比锁更加方便。如果一个字段被声明成 volatile,java 线程内存模型确保所有线程看到这个变量的值是一致的。
特性:
- 可见性 : 对一个 volatile 的变量的读,总是能看到任意线程对这个变量最后的写入.
- 单个读或者写具有原子性 : 对于单个 volatile 变量的读或者写具有原子性,复合操作不具有.(如 i++)
- 互斥性 : 同一时刻只允许一个线程对变量进行操作.(互斥锁的特点)
# 写-读建立的 happens-before 关系
从 JSR-133 开始 (即从 JDK5 开始),volatile 变量的写-读可以实现线程之间的通信。从内存语义的角度来说:
- volatile 的写-读与锁的释放-获取有相同的内存效果:
- volatile 写和锁的释放有相同的内存语义;volatile 读与锁的获取有相同的内存语义。
public class VolatileExample {
int a = 0; // 普通共享变量
volatile boolean flag = false; // volatile 共享变量
public void writer() { // 写线程 A 操作
a = 1; //1
flag = true; //2
}
public void reader() { // 读线程 B 操作
if (flag) { //3
int i = a; //4
System.out.printf(String.valueOf(i));
// do something ...
}
}
}
假设线程 A 执行 writer() 方法之后,线程 B 执行 reader() 方法。
根据 happens-before 规则,这个过程建立的 happens-before 关系可以分为 3 类:
- 根据程序次序规则,1 happens-before 2;3 happens-before 4。
- 根据 volatile 规则,2 happens-before 3。(重点)
- 根据 happens-before 的传递性规则,1 happens-before 4。
上述 happens-before 关系的图形化表现形式如下:
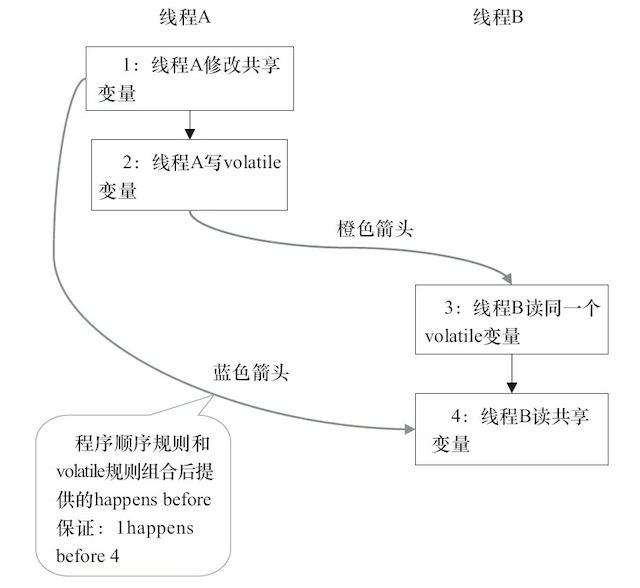
在上图中,每一个箭头链接的两个节点,代表了一个 happens-before 关系。
- 黑色箭头:表示程序顺序规则;
- 橙色箭头:表示 volatile 规则;
- 蓝色箭头:表示组合这些规则后提供的 happens-before 保证。
这里 A 线程写一个 volatile 变量后,B 线程读同一个 volatile 变量。A 线程在写 volatile 变量之 前所有可见的共享变量,在 B 线程读同一个 volatile 变量后,将立即变得对 B 线程可见。
# 写-读的内存语义
- volatile 写的内存语义:当写一个 volatile 变量时,JMM 会把该线程对应的本地内存中的共享变量值刷新到主内存
- volatile 读的内存语义:当读一个 volatile 变量时,JMM 会把该线程对应的本地内存置为无效。线程接下来将从主内存中读取共享变量。
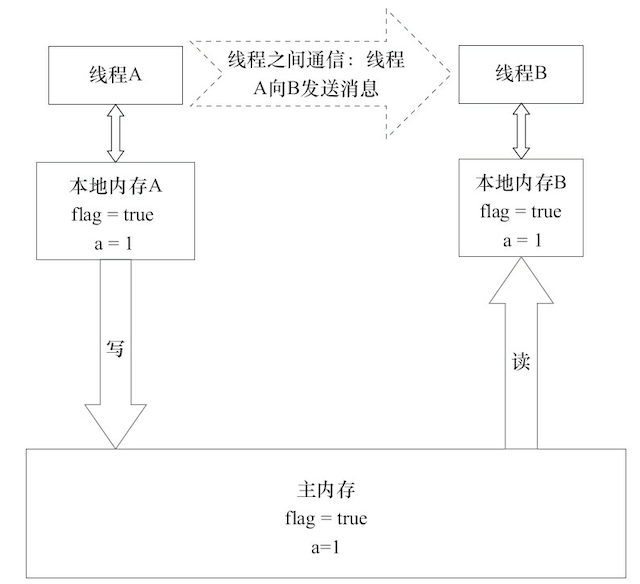
如果我们把 volatile 写和 volatile 读两个步骤综合起来看的话,在读线程 B 读一个 volatile 变量后,写线程 A 在写这个 volatile 变量之前所有可见的共享变量的值都将立即变得对读线程 B 可见。
下面对 volatile 写和 volatile 读的内存语义做个总结。
- 线程 A 写一个 volatile 变量,实质上是线程 A 向接下来将要读这个 volatile 变量的某个线程发出了 (其对共享变量所做修改的) 消息。
- 线程 B 读一个 volatile 变量,实质上是线程 B 接收了之前某个线程发出的 (在写这个 volatile 变量之前对共享变量所做修改的) 消息。
- 线程 A 写一个 volatile 变量,随后线程 B 读这个 volatile 变量,这个过程实质上是线程 A 通过主内存向线程 B 发送消息。
# 内存语义的实现?
JMM 如何实现 volatile 写/读的内存语义?《基础概念》中提到过重排序分为编译器重排序和处理器重排序。为了实现 volatile 内存语义,JMM 会分别限制这两种类型的重排序类型。
该表为 JMM 针对编译器制定的 volatile 重排序规则:

- 当第二个操作是 volatile 写时,不管第一个操作是什么,都不能重排序。这个规则确保 volatile 写之前的操作不会被编译器重排序到 volatile 写之后。
- 当第一个操作是 volatile 读时,不管第二个操作是什么,都不能重排序。这个规则确保 volatile 读之后的操作不会被编译器重排序到 volatile 读之前。
- 当第一个操作是 volatile 写,第二个操作是 volatile 读时,不能重排序。
对于编译器来说,发现一个最优布置来最小化插入屏障的总数几乎不可能。为此,JMM 采取保守策略。下面是基于保守策略的 JMM 内存屏障插入策略:
- 在每个 volatile 写操作的前面插入一个 StoreStore 屏障。
- 在每个 volatile 写操作的后面插入一个 StoreLoad 屏障。
- 在每个 volatile 读操作的后面插入一个 LoadLoad 屏障。
- 在每个 volatile 读操作的后面插入一个 LoadStore 屏障。
上述内存屏障插入策略非常保守,但它可以保证在任意处理器平台,任意的程序中都能得到正确的 volatile 内存语义。
在实际执行时,只要不改变 volatile 写-读的内存语义,编译器可以根据具体情况省略不必要的屏障。
《final 域的内存语义#final 语义在处理器中的实现》提到过,X86 处理器仅会对写-读操作做重排序。X86 不会对读-读、读-写和写-写操作做重排序,因此在 X86 处理器中会省略掉这 3 种操作类型对应的内存屏障。
在 X86 中,JMM 仅需在 volatile 写后面插入一个 StoreLoad 屏障即可正确实现 volatile 写-读的内存语义。
这意味着在 X86 处理器中 volatile 写的开销比 volatile 读的开销会大很多 (因为执行 StoreLoad 屏障开销会比较大)。
# 写插入内存屏障后生成的指令序列
volatile 写插入内存屏障后生成的指令序列示意图如下:
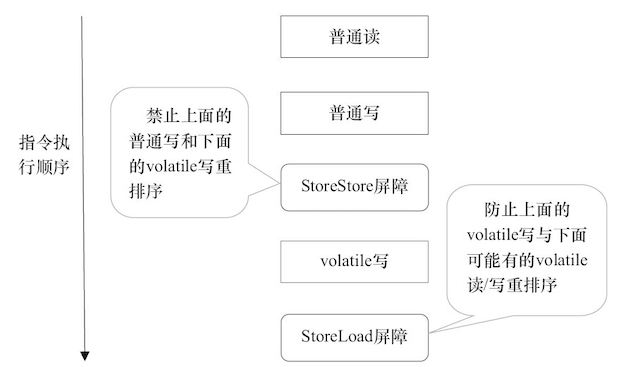
图中的 StoreStore 屏障可以保证在 volatile 写之前,其前面的所有普通写操作已经对任意处理器可见了。这是因为 StoreStore 屏障将保障上面所有的普通写在 volatile 写之前刷新到主内存。
volatile 写后面的 StoreLoad 屏障作用是避免 volatile 写与后面可能有的 volatile 读/写操作重排序。
因为编译器常常无法准确判断在一个 volatile 写的后面 是否需要插入一个 StoreLoad 屏障 (比如,一个 volatile 写之后方法立即 return)。
为了保证能正确实现 volatile 的内存语义,JMM 在采取了保守策略:在每个 volatile 写的后面,或者在每个 volatile 读的前面插入一个 StoreLoad 屏障。
从整体执行效率的角度考虑,JMM 最终选择了在每个 volatile 写的后面插入一个 StoreLoad 屏障。因为 volatile 写-读内存语义的常见使用模式是:一个写线程写 volatile 变量,多个读线程读同一个 volatile 变量。当读线程的数量大大超过写线程时,选择在 volatile 写之后插入 StoreLoad 屏障将带来可观的执行效率的提升。从这里可以看到 JMM 在实现上的一个特点:首先确保正确性,然后再去追求执行效率。
# 读插入内存屏障后生成的指令序列
volatile 读插入内存屏障后生成的指令序列示意图如下:

图中的 LoadLoad 屏障用来禁止处理器把上面的 volatile 读与下面的普通读重排序。LoadStore 屏障用来禁止处理器把上面的 volatile 读与下面的普通写重排序。
WARNING
上述volatile写和volatile读的内存屏障插入策略非常保守。在实际执行时,只要不改变 volatile写-读的内存语义,编译器可以根据具体情况省略不必要的屏障。
# JSR-133 为什么要增强 volatile 内存语义
在 JSR-133 之前的旧 Java 内存模型中,虽然不允许 volatile 变量之间重排序,但旧的 Java 内存模型允许 volatile 变量与普通变量重排序。 在旧的内存模型中,VolatileExample 示例程序可能 被重排序成下列时序来执行
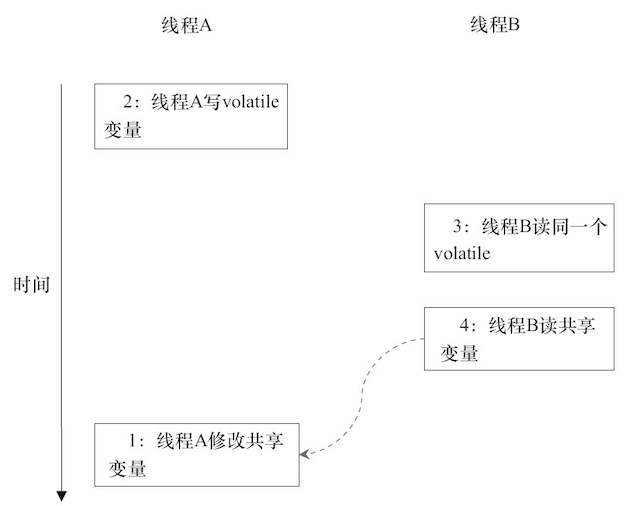
在旧的内存模型中,当 1 和 2 之间没有数据依赖关系时,1 和 2 之间就可能被重排序(3 和 4 类似)。
其结果就是:读线程 B 执行 4 时,不一定能看到写线程 A 在执行 1 时对共享变量的修改。
因此,在旧的内存模型中,volatile 的写-读没有锁的释放-获所具有的内存语义。 为了提供一种比锁更轻量级的线程之间通信的机制,JSR-133 专家组决定增强 volatile 的内存语义:严格限制编译器和处理器对 volatile 变量与普通变量的重排序,确保 volatile 的写-读和锁的释放-获取具有相同的内存语义。 从编译器重排序规则和处理器内存屏障插入策略来看,只要 volatile 变量与普通变量之间的重排序可能会破坏 volatile 的内存语义,这种重排序就会被编译器重排 序规则和处理器内存屏障插入策略禁止。
# 应用场景
您只能在有限的一些情形下使用 volatile 变量替代锁。要使 volatile 变量提供理想的线程安全,必须同时满足下面两个条件:
不变式:(例如 “start <=end”)
- 对变量的写操作不依赖于当前值。
- 该变量没有包含在具有其他变量的不变式中。
详细解释:
第一个条件,因为 volatile 不支持增量操作(i++),即单个读写操作可以保证原子性,但组合操作(++,读取-修改-写入操作序列组成的组合操作)不具有原子性。
第一个条件,例如下面VolatileNumberRange示例了一个不变式的类。如果初始状态是 (0, 5),同一时间内,线程 A 调用 setLower(4) 并且线程 B 调用 setUpper(3),显然这两个操作交叉存入的值是不符合条件的,那么两个线程都会通过用于保护不变式的检查,使得最后的范围值是 (4, 3) —— 一个无效值。
至于针对范围的其他操作,我们需要使 setLower() 和 setUpper() 操作原子化 —— 而将字段定义为 volatile 类型是无法实现这一目的的。
@NotThreadSafe
public class VolatileNumberRange {
private int lower, upper;
public int getLower() { return lower; }
public int getUpper() { return upper; }
public void setLower(int value) {
if (value > upper)
throw new IllegalArgumentException("...");
lower = value;
}
public void setUpper(int value) {
if (value < lower)
throw new IllegalArgumentException("...");
upper = value;
}
}
# volatile 的性能考量
- 使用 volatile 变量的主要原因是其简易性:在某些情形下,使用 volatile 变量要比使用相应的锁简单得多。
- 使用 volatile 变量次要原因是其性能:某些情况下,volatile 变量同步机制的性能要优于锁。
很难做出准确、全面的评价,例如 “X 总是比 Y 快”,尤其是对 JVM 内在的操作而言。(例如,某些情况下 VM 也许能够完全删除锁机制,这使得我们难以抽象地比较 volatile 和 synchronized 的开销。)就是说,在目前大多数的处理器架构上,volatile 读操作开销非常低 —— 几乎和非 volatile 读操作一样。而 volatile 写操作的开销要比非 volatile 写操作多很多,因为要保证可见性需要实现内存界定(Memory Fence),即便如此,volatile 的总开销仍然要比锁获取低。
volatile 操作不会像锁一样造成阻塞,因此,在能够安全使用 volatile 的情况下,volatile 可以提供一些优于锁的可伸缩特性。如果读操作的次数要远远超过写操作,与锁相比,volatile 变量通常能够减少同步的性能开销。
# 正确使用 volatile 的模式
始终牢记使用 volatile 的限制:只有在状态真正独立于程序内其他内容时才能使用 volatile。
# 模式:状态标志
仅仅是使用一个布尔状态标志,用于指示发生了一个重要的一次性事件,例如完成初始化或请求停机。
volatile boolean shutdownRequested;
public void shutdown() { shutdownRequested = true; }
public void doWork() {
while (!shutdownRequested) {
// do stuff
}
}
# 模式:一次性安全发布
缺乏同步会导致无法实现可见性,这使得确定何时写入对象引用而不是原语值变得更加困难。 在缺乏同步的情况下,可能会遇到某个对象引用的更新值(由另一个线程写入)和该对象状态的旧值同时存在。 (这就是造成著名的双重检查锁定(double-checked-locking)问题的根源,其中对象引用在没有同步的情况下进行读操作,产生的问题是您可能会看到一个更新的引用,但是仍然会通过该引用看到不完全构造的对象)。
该模式的一个必要条件是:被发布的对象必须是线程安全的,或者是有效的不可变对象(有效不可变意味着对象的状态在发布之后永远不会被修改)。volatile 类型的引用可以确保对象的发布形式的可见性,但是如果对象的状态在发布后将发生更改,那么就需要额外的同步。
# 模式:独立观察
定期 “发布” 观察结果供程序内部使用。
使用
public volatile String lastUser;保存最后一个用户状态(每次被新来的用户替换),供其他方法读取。
# 模式:volatile bean
volatile bean 模式的基本原理是:很多框架为易变数据的持有者(例如 HttpSession)提供了容器,但是放入这些容器中的对象必须是线程安全的。
volatile bean 模式中,JavaBean 的所有数据成员都是 volatile 类型的,并且 getter 和 setter 方法必须非常普通 —— 除了获取或设置相应的属性外,不能包含任何逻辑。
此外,对于对象引用的数据成员,引用的对象必须是有效不可变的。(这将禁止具有数组值的属性,因为当数组引用被声明为 volatile 时,只有引用而不是数组本身具有 volatile 语义)。对于任何 volatile 变量,不变式或约束都不能包含 JavaBean 属性。
# 模式:开销较低的读-写锁策略
如果读操作远远超过写操作,您可以结合使用内部锁和 volatile 变量来减少公共代码路径的开销。
@ThreadSafe
public class CheesyCounter {
// 使用当前对象 'this' 作为锁
@GuardedBy("this") private volatile int value;
public int getValue() { return value; }
public synchronized int increment() {
return value++;
}
}
# 思考
- volatile 关键字的作用、原理
- 什么时候选择用 volatile
- volatile、synchronized、CAS 操作的区别及应用场景