专栏原创出处:github-源笔记文件 (opens new window) ,github-源码 (opens new window),欢迎 Star,转载请附上原文出处链接和本声明。
Java 并发编程专栏系列笔记,系统性学习可访问个人复盘笔记-技术博客 Java 并发编程 (opens new window)
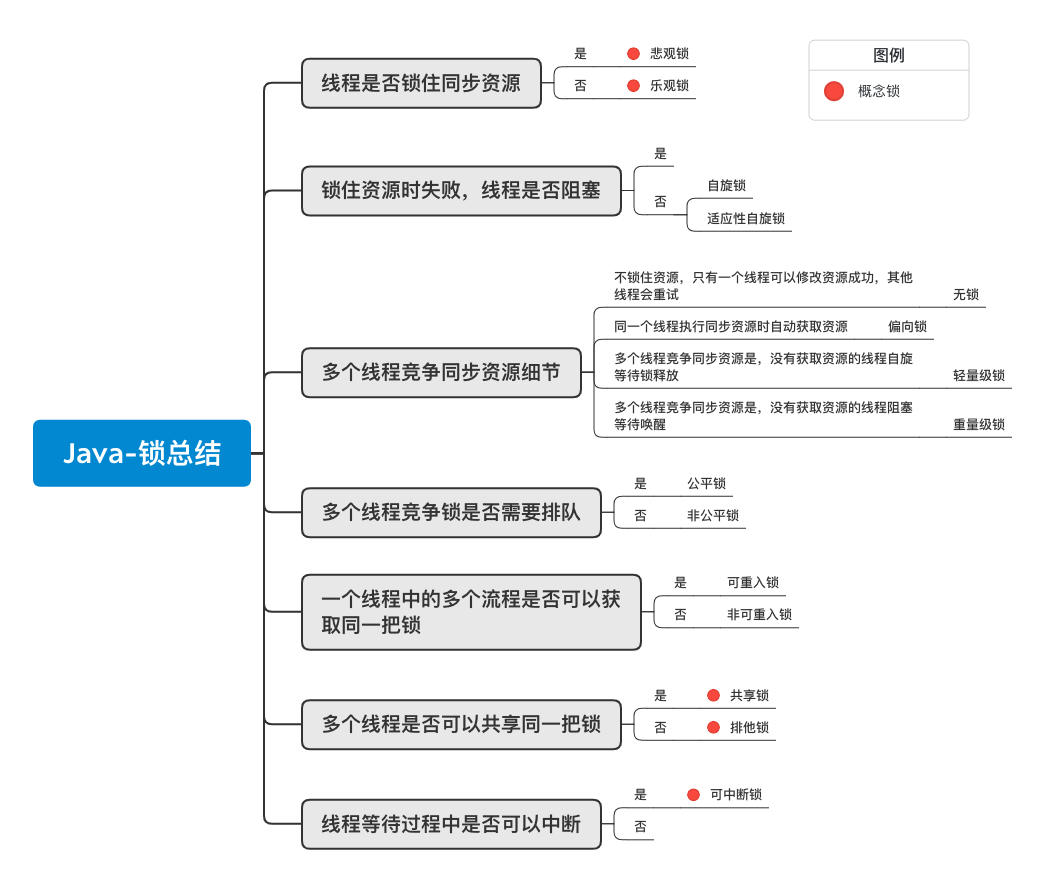
# 锁类型总结
关于锁的知识点参考《锁的内存语义》《并发操作比较(CAS、volatile、synchronized、Lock)》文章,该文章仅作为锁的概念汇总与实现举例,实现举例不代表所有实现。想要加深对锁的理解请系统性的学习 Java 并发编程相关知识,更深入了解各种锁的设计由来及执行机制。
Java 锁的分类没有严格意义的规则,我们常说的分类一般都是依据锁的特性、锁的设计、锁的状态等进行归纳整理。
- 乐观锁、悲观锁
- 自旋锁、适应性自旋锁
- 无锁、偏向锁、轻量级锁、重量级锁
- 公平锁、非公平锁
- 可重入锁、非可重入锁
- 排他锁、共享锁
- 读写锁
- 分段锁
- 可中断锁
# 乐观锁、悲观锁
乐观锁与悲观锁是一种广义上的概念,体现了看待线程同步的不同角度。在 Java 和数据库中都有此概念对应的实际应用。
对于同一个数据的并发操作:
- 悲观锁:认为自己在使用数据的时候一定有别的线程来修改数据,因此在获取数据的时候会先加锁,确保数据不会被别的线程修改。
- 乐观锁:认为自己在使用数据时不会有别的线程修改数据,所以不会添加锁,只是在更新数据的时候去判断之前有没有别的线程更新了这个数据。如果这个数据没有被更新,当前线程将自己修改的数据成功写入。如果数据已经被其他线程更新,则根据不同的实现方式执行不同的操作(例如报错或者自动重试)。
# 实现
- 乐观锁
- 在 Java 中是通过使用无锁编程来实现,最常采用的是CAS 算法,Java 原子类中的递增操作就通过 CAS 自旋实现的。
- 悲观锁
- synchronized
- Lock 实现类
# 场景分析
- 乐观锁适合读操作多的场景,不加锁的特点能够使其读操作的性能大幅提升。
- 悲观锁适合写操作多的场景,先加锁可以保证写操作时数据正确。
# 自旋锁、适应性自旋锁
# 自旋锁的概念
阻塞或唤醒一个 Java 线程需要操作系统切换 CPU 状态来完成,这种状态转换需要耗费处理器时间。如果同步代码块中的内容过于简单,状态转换消耗的时间有可能比用户代码执行的时间还要长。
在许多场景中,同步资源的锁定时间很短,为了这一小段时间去切换线程,线程挂起和恢复现场的花费可能会让系统得不偿失。如果物理机器有多个处理器,能够让两个或以上的线程同时并行执行,我们就可以让后面那个请求锁的线程不放弃 CPU 的执行时间,看看持有锁的线程是否很快就会释放锁。
为了让当前线程“稍等一下”,我们需让当前线程进行自旋,如果在自旋完成后前面锁定同步资源的线程已经释放了锁,那么当前线程就可以不必阻塞而是直接获取同步资源,从而避免切换线程的开销。这就是自旋锁。
在自旋锁中 另有三种常见的锁形式:TicketLock、CLHlock 和 MCSlock,感兴趣的同学可以查阅相关资料。
# 适应性自旋锁
自旋锁在 JDK1.4.2 中引入,使用-XX:+UseSpinning 来开启。JDK 6 中变为默认开启,并且引入了自适应的自旋锁(适应性自旋锁)。 自适应意味着自旋的时间(次数)不再固定,而是由前一次在同一个锁上的自旋时间及锁的拥有者的状态来决定。
- 如果在同一个锁对象上,自旋等待刚刚成功获得过锁,并且持有锁的线程正在运行中,那么虚拟机就会认为这次自旋也是很有可能再次成功,进而它将允许自旋等待持续相对更长的时间。
- 如果对于某个锁,自旋很少成功获得过,那在以后尝试获取这个锁时将可能省略掉自旋过程,直接阻塞线程,避免浪费处理器资源。
# 缺点
自旋锁本身是有缺点的,它不能代替阻塞。自旋等待虽然避免了线程切换的开销,但它要占用处理器时间。如果锁被占用的时间很短,自旋等待的效果就会非常好。反之,如果锁被占用的时间很长,那么自旋的线程只会白浪费处理器资源。
所以,自旋等待的时间必须要有一定的限度,如果自旋超过了限定次数(默认是 10 次,可以使用-XX:PreBlockSpin 来更改)没有成功获得锁,就应当挂起线程。
# 实现
- 自旋锁的实现原理同样也是 CAS。
AtomicInteger 中调用 unsafe 进行自增操作的源码中的 do-while 循环就是一个自旋操作,如果修改数值失败则通过循环来执行自旋,直至修改成功。
# 无锁、偏向锁、轻量级锁、重量级锁
Java SE 1.6 为了减少获得锁和释放锁带来的性能消耗,引入了 “偏向锁” 和 “轻量级锁”。
Java SE 1.6 中,锁一共有 4 种状态,级别从低到高依次是: 无锁状态、偏向锁状态、轻量级锁状态和重量级锁状态,这几个状态会随着竞争情况逐渐升级。
锁可以升级但不能降级,意味着偏向锁升级成轻量级锁后不能降级成偏向锁。这种锁升级却不能降级的策略,目的是为了提高获得锁和释放锁的效率。
详细锁升级过程请参考本专栏文章《并发关键字-synchronized》中 synchronized 锁的升级与对比章节。
# 实现
- synchronized
# 公平锁、非公平锁
# 公平锁
公平锁是指多个线程按照申请锁的顺序来获取锁,线程直接进入队列中排队,队列中的第一个线程才能获得锁。
- 优点是等待锁的线程不会饿死。
- 缺点是整体吞吐效率相对非公平锁要低,等待队列中除第一个线程以外的所有线程都会阻塞,CPU 唤醒阻塞线程的开销比非公平锁大。
# 非公平锁
非公平锁是多个线程加锁时直接尝试获取锁,获取不到才会到等待队列的队尾等待。但如果此时锁刚好可用,那么这个线程可以无需阻塞直接获取到锁,所以非公平锁有可能出现后申请锁的线程先获取锁的场景。
- 优点是可以减少唤起线程的开销,整体的吞吐效率高,因为线程有几率不阻塞直接获得锁,CPU 不必唤醒所有线程。
- 缺点是处于等待队列中的线程可能会饿死,或者等很久才会获得锁。
# 实现
- ReentrantLock
- ReentrantReadWriteLock
# 可重入锁、非可重入锁
可重入锁又名递归锁,是指在同一个线程在外层方法获取锁的时候,再进入该线程的内层方法会自动获取锁(前提锁对象得是同一个对象或者 class),不会因为之前已经获取过还没释放而阻塞。可重入锁的一个优点是可一定程度避免死锁。
# 为什么非可重入锁会出现死锁?
ReentrantLock 和 synchronized 都是重入锁,那么我们通过重入锁 ReentrantLock 以及非可重入锁 NonReentrantLock 的源码来对比分析一下为什么非可重入锁在重复调用同步资源时会出现死锁。
ReentrantLock 继承父类 AQS,AQS 中维护了一个同步状态 status 来计数重入次数,status 初始值为 0。
- 获取锁时
- 可重入锁先尝试获取并更新 status 值,如果 status == 0 表示没有其他线程在执行同步代码,则把 status 置为 1,当前线程开始执行。如果 status != 0,则判断当前线程是否是获取到这个锁的线程,如果是的话执行 status+1,且当前线程可以再次获取锁。
- 非可重入锁是直接去获取并尝试更新当前 status 的值,如果 status != 0 的话会导致其获取锁失败,当前线程阻塞。
- 释放锁时
- 可重入锁同样先获取当前 status 的值,在当前线程是持有锁的线程的前提下。如果 status-1 == 0,则表示当前线程所有重复获取锁的操作都已经执行完毕,然后该线程才会真正释放锁。
- 非可重入锁则是在确定当前线程是持有锁的线程之后,直接将 status 置为 0,将锁释放。
# 实现
- 可重入锁
- ReentrantLock
- synchronized
- ReentrantReadWriteLock 的读写锁
- 非可重入锁
- 暂无
# 排他锁、共享锁
排他锁和共享锁同样是一种概念。
排他锁是指该锁一次只能被一个线程所持有。如果线程 T 对数据 A 加上排它锁后,则其他线程不能再对 A 加任何类型的锁。获得排它锁的线程即能读数据又能修改数据。
共享锁是指该锁可被多个线程所持有。如果线程 T 对数据 A 加上共享锁后,则其他线程只能对 A 再加共享锁,不能加排它锁。获得共享锁的线程只能读数据,不能修改数据。
通过 ReentrantLock 和 ReentrantReadWriteLock 的源码来介绍排他锁和共享锁。 排他锁与共享锁也是通过 AQS 来实现的,通过实现不同的方法,来实现独享或者共享。
# ReentrantReadWriteLock 分析
我们看到 ReentrantReadWriteLock 有两把锁:ReadLock 和 WriteLock,一个读锁一个写锁,合称“读写锁”。 进一步观察可以发现 ReadLock 和 WriteLock 是靠内部类 Sync 实现的锁。Sync 是 AQS 的一个子类,这种结构在 CountDownLatch、ReentrantLock、Semaphore 里面也都存在。 在 ReentrantReadWriteLock 里面,读锁和写锁的锁主体都是 Sync,但读锁和写锁的加锁方式不一样。
读锁是共享锁,写锁是排他锁。读锁的共享锁可保证并发读非常高效,而读写、写读、写写的过程互斥,因为读锁和写锁是分离的。所以 ReentrantReadWriteLock 的并发性相比一般的互斥锁有了很大提升。
# ReentrantLock 分析
我们发现在 ReentrantLock 虽然有公平锁和非公平锁两种,但是它们添加的都是排他锁。根据源码所示,当某一个线程调用 lock 方法获取锁时,如果同步资源没有被其他线程锁住,那么当前线程在使用 CAS 更新 state 成功后就会成功抢占该资源。而如果公共资源被占用且不是被当前线程占用,那么就会加锁失败。所以可以确定 ReentrantLock 无论读操作还是写操作,添加的锁都是都是排他锁。
# 实现
- 排他锁
- synchronized
- Lock 相关实现类,ReentrantReadWriteLock 写锁
- Lock 相关实现类,ReentrantLock
- 共享锁
- ReentrantReadWriteLock 读锁
# 读写锁
参考 排他锁、共享锁 中针对ReentrantReadWriteLock 读写锁简单分析,更深入的了解(请参考本专栏文章《锁-读写锁(ReentrantReadWriteLock)》)
# 分段锁
实质是一种锁的设计策略,不是具体的锁,对于 ConcurrentHashMap 而言其并发的实现就是通过分段锁的形式来实现高效并发操作。
当要 put 元素时并不是对整个 hashMap 加锁,而是先通过 hashcode 知道它要放在哪个分段,然后对分段进行加锁,所以多线程 put 元素时只要放在的不是同一个分段就做到了真正的并行插入,但是统计 size 时就需要获取所有的分段锁才能统计。
分段锁的设计是为了细化锁的粒度。
# 可中断锁
synchronized 是不可中断的,Lock 是可中断的,这里的可中断建立在阻塞等待中断,运行中是无法中断的。
# 实现
- Lock 实现类提供响应中断状态的加锁
# 参考
- 请参考本专栏文章《锁的内存语义》ReentrantLock 加锁解锁过程分析
- 请参考本专栏文章《锁-读写锁(ReentrantReadWriteLock)》
- 请参考本专栏文章《锁-重入锁(ReentrantLock)》
- 【基本功】不可不说的 Java “锁” 事 (opens new window)
← 锁-死锁问题及解决方案 并发容器-阻塞队列 →