专栏原创出处:github-源笔记文件 (opens new window) ,github-源码 (opens new window),欢迎 Star,转载请附上原文出处链接和本声明。
# 1.数组
数组是一种基本的数据结构,用于按顺序存储元素的集合。但是元素可以随机存取,因为数组中的每个元素都可以通过数组索引来识别。
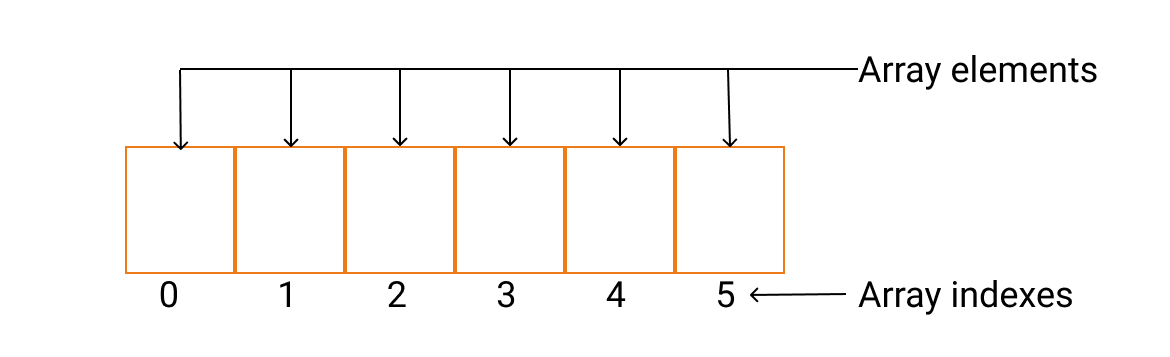
- 索引(indexes):元素在数据中的位置,从 0 开始。
- 元素(elements):存储在数组的项目为元素,可以通过索引访问。
- 长度(length):数组可以存储的元素个数。
# 1.1 数组的特点
固定大小。因为采用顺序存储结构,需要连续的内存空间,初始化时必须指定长度。
数组仅支持查询与修改操作。
查询修改快。连续的内存空间可直接采用「基地址 + i * data_size」寻址。
插入删除慢。因为操作后需要移动其余的元素。
# 1.2 为什么下标从 0 开始
上述特点中数组查询方式的寻址方式决定,使用 0 可减少 CPU 操作。如果是从 1 开始,a[i] = 基地址 + (i-1)* data_size 多了一个减法指令。
# 1.3 多维数组
平常我们一般所说的数组是一维数组。
定义一个二维数组如下。
[
[ 1, 2, 3 ],
[ 4, 5, 6 ],
[ 7, 8, 9 ]
]
因为多维关系与一维存储地址之间存在唯一的映射问题,需要对高维数组元素的存放次序进行约定。n 维数组通常有两种存放次序:
- 按行优先顺序:将高位数组元素按行向量的顺序存储,第 i+1 个行向量存储在第 i 个行向量之后。
- 按列优先顺序:将数组元素按列向量的顺序存储,第 i+1 个列向量存储在第 i 个列向量之后。
# 1.4 动态数组
因为数组是固定大小的,实际编程中数据内容的大小我们不确定,需要根据实际情况动态扩展。
大多数编程语言都提供内置的动态数组,它仍然是一个随机存取的列表数据结构,但大小是可变的。例如,在 C++ 中的 vector,以及在 Java 中的 ArrayList。
# 2. 字符串
字符串实际上是一个字符数组。通常编程操作中离不开字符串操作,语言本身为我们提供了字符串的常用方法。对于字符串的操作一般底层操作字符数组完成。
# 3.数组字符串算法总结
# 3.1 双指针技巧
技巧一: 对撞指针,两个指针从两端向中间迭代
关键词:反转
经典示例:反转数组中的元素
public static void reverse(int[] v, int N) {
int i = 0;
int j = N - 1;
while (i < j) {
swap(v, i, j); // this is a self-defined function
i++;
j--;
}
}
技巧二: 滑动窗口,一个快指针,一个慢指针
关键词:移除、重置、包含子串
经典示例:给定一个数组和一个值,原地删除该值的所有实例并返回新的长度
public int removeElement(int[] nums, int val) {
int k = 0;
for (int i = 0; i < nums.length; ++i) {
if (nums[i] != val) {
nums[k] = nums[i];
k++;
}
}
return k;
}
# 4.算法实践
推荐完成
# 参考
更多相关专栏内容汇总:

← 时间复杂度与空间复杂度 链表 →