# 1.链表
链表作为一种基础的数据结构可以用来生成其它类型的数据结构。通常由一连串节点组成,每个节点包含任意的实例数据(data)和一或两个用来指向上一个/或下一个节点的位置的链接。
我们通过下图可直观的比对数组与链表的结构。
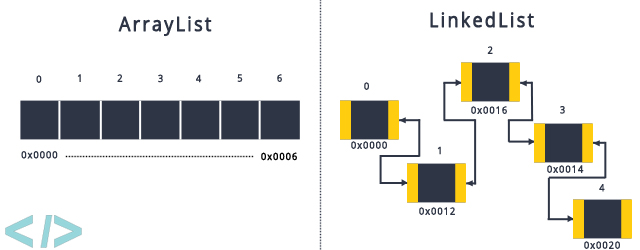
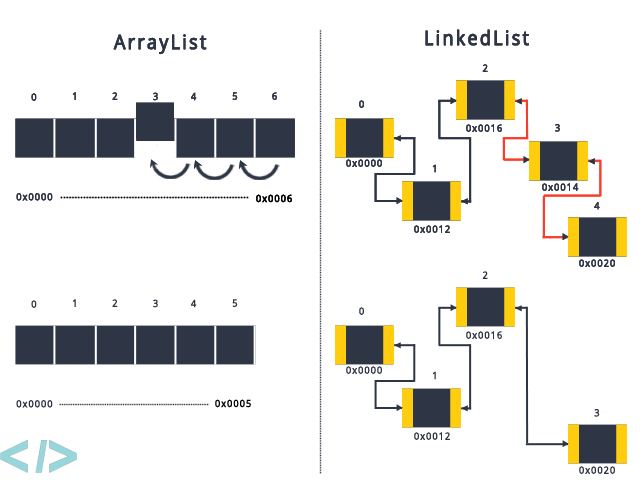
比如我们删除第「3」个元素时,两种数据结构的操作差异性如下:
# 1.1 链表的特点
- 灵活的内存分配,不需要连续的内存空间。
- 查询慢。不能随机访问,需要迭代整个链表。时间复杂度为 O(n),n 为链表长度。
- 修改删除快。只需要操作对应节点的数据就可以。时间复杂度为 O(1)。
# 1.2 链表的类型
根据链表节点内部维护的指针及头尾节点引用维护动作情况可分为单链表、双向链表、单向循环链表、双向循环列表。
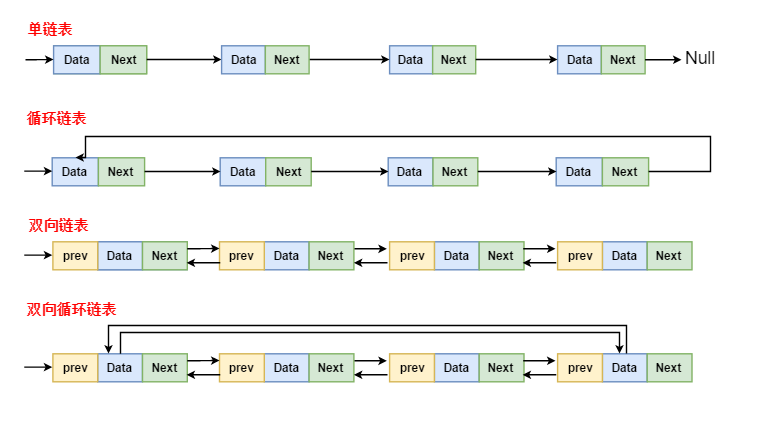
来源:https://www.jianshu.com/p/a3698e4f0414
# 1.3 时间复杂对比对
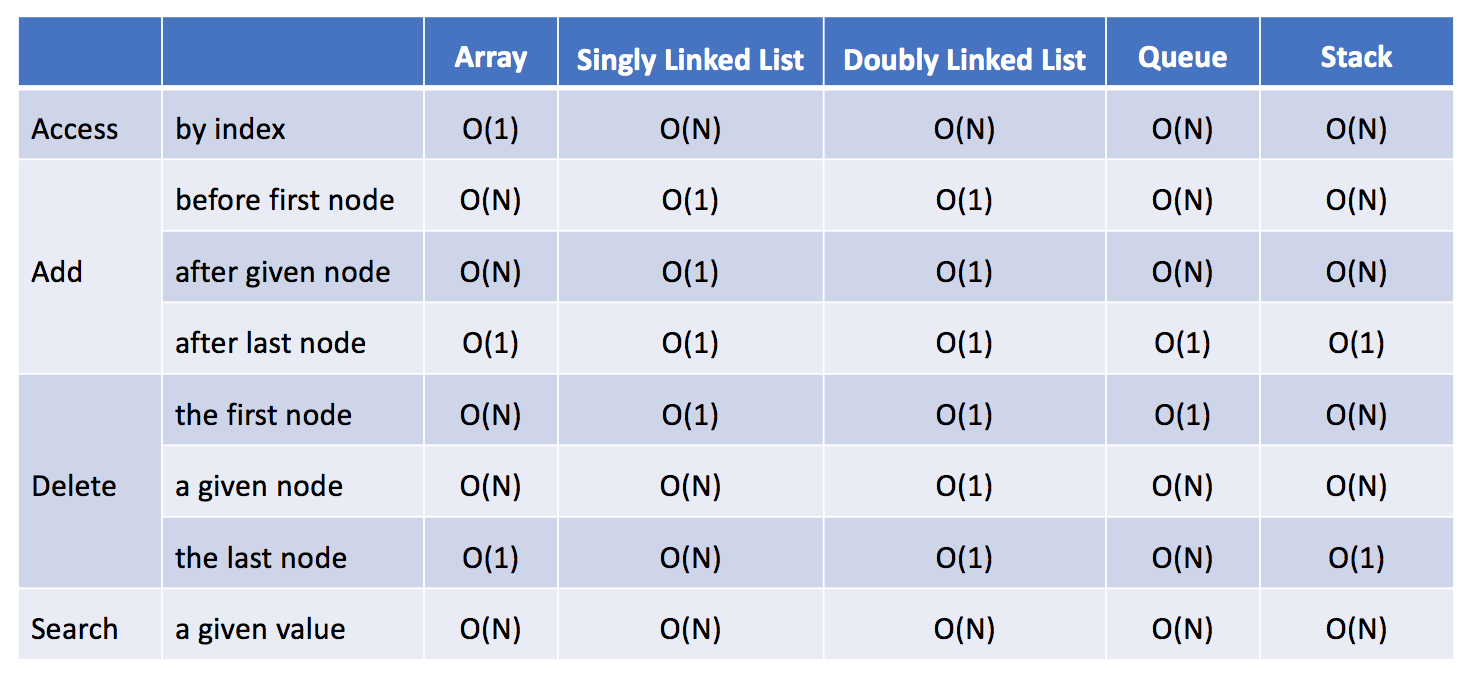
来源:https://leetcode-cn.com/explore/learn/card/linked-list/197/conclusion/761/
如果你需要经常添加或删除结点,链表可能是一个不错的选择。
如果你需要经常按索引访问元素,数组可能是比链表更好的选择。
# 2.单链表
每个节点仅有一个后驱指针。
// 单链表-节点定义.
public class SinglyListNode {
int val;
SinglyListNode next; // 后驱节点
SinglyListNode(int x) { val = x; }
}
优点:插入/删除数据:因为不需要移动数据,只需要在操作位前后修改数据,仅单独操作考虑,时间复杂度位 O(1)
缺点:随机访问第 K 个元素需要根据指一个一个遍历,时间复杂度位 O(n)
# 3.单向循环链表
在单链表的基础上,尾节点的 next 指针指向头节点地址,使链表首尾相连
优点:从表中任一节点出发都能遍历整个链表
# 4.双向链表
每个节点有前驱和后驱两个指针。
在单链表中,它无法获取给定结点的前一个结点,因此在删除给定结点之前我们必须花费 O(N) 时间来找出前一结点。
在双链表中,这会更容易,因为我们可以使用“prev”引用字段获取前一个结点。因此我们可以在 O(1) 时间内删除给定结点。
// 双向链表-节点定义.
class DoublyListNode {
int val;
DoublyListNode next, prev; // 后驱、前驱节点
DoublyListNode(int x) {val = x;}
}
优点:双向链表可以根据查询索引判断遍历的方向。
// 寻找 index 所在的节点
private Node findCurrNode(int index) {
if (index == 0) return head;
if (index == size - 1) return tail;
Node pred;
if (index > size >> 1) { // 判断头部、尾部遍历
pred = tail;
for (int i = size - 1; i > index; i--) pred = pred.first;
} else {
pred = head;
for (int i = 0; i < index; ++i) pred = pred.last;
}
return pred;
}
缺点:占用了更多的内存空间。最坏的情况下,时间复杂度将是 O(N),其中 N 是链表的长度。
# 5.双向循环链表
在双向链表的基础上,将首尾两个节点相连接起来。
优点:从表中任一节点出发都能遍历整个链表
# 6.实践
推荐完成
- 关于单链表、双链表的实现源码可参考 GitHub (opens new window)
- LeetCode-探索-链表 (opens new window)
# 参考
- 维基百科-链表 (opens new window)
- 力扣-探索-链表 (opens new window)
- 力扣刷题总结之链表 (opens new window)
- codenuclear-Difference between ArrayList and LinkedList (opens new window)
更多相关专栏内容汇总:
