专栏原创出处:github-源笔记文件 (opens new window) ,github-源码 (opens new window),欢迎 Star,转载请附上原文出处链接和本声明。
# 1. 递归的定义
编程语言中,函数Func(Type a,……)直接或间接调用函数本身,则该函数称为「递归函数」。
在实现递归函数之前,有两件重要的事情需要弄清楚:
- 递推关系:一个问题的结果与其子问题的结果之间的关系。
- 基本情况:不需要进一步的递归调用就可以直接计算答案的情况。可理解为递归跳出条件。
一旦我们计算出以上两个元素,再想要实现一个递归函数,就只需要根据递推关系调用函数本身,直到其抵达基本情况。
# 1.1 递推关系
下面的插图给出了一个 5 行的帕斯卡三角,根据上面的定义,我们生成一个具有确定行数的帕斯卡三角形。
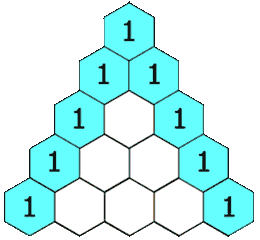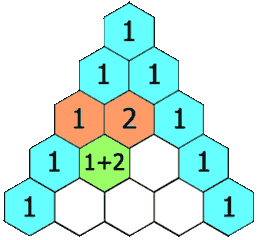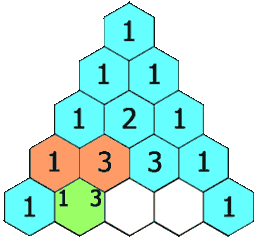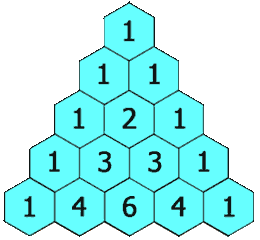
来源力扣
首先,我们定义一个函数 ,它将会返回帕斯卡三角形第 行、第 列的数字。可以看到,每行的最左边和最右边的数字是基本情况,它总是等于 。 每个数是它左上方和右上方的数的和。
- 递推关系:
- 基本情况: ,当 或者 时。
# 1.2 尾递归
尾递归:函数中所有的递归形式都出现在函数末尾时。
递归函数的编写看起来比较难,其实是有套路可寻的,本问总结了写递归的一些范式技巧并在后续实战中进行验证。
# 2. 如何写出一个递归函数
下面我们以累加的示例说明写递归的思路。
,函数表达式为
# 2.1 寻找基本情况
累加示例中,基本情况为 时,。
你也可以设定为 ,只要能正确跳出递归即可。
# 2.2 寻找递推关系(难点)
累加示例中,递推关系为 , 每次执行时依赖 的结果,所以我们把 的结果看作是中间变量。
中间变量其实就是联系递归函数的纽带,分析出中间变量递归函数也就实现了 80%。
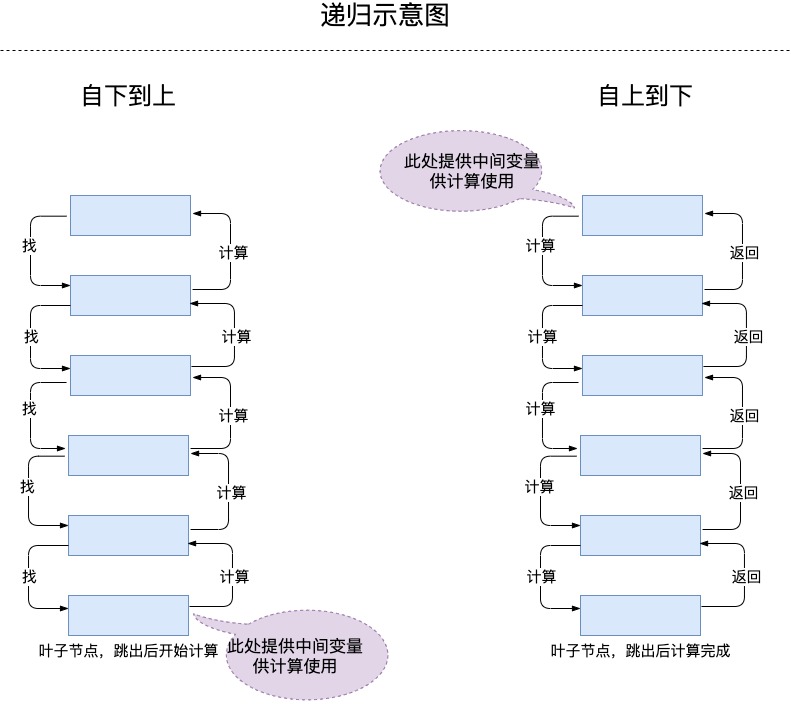
大白话:当前结果必须借助前一个结果,前一个借助前前一个... 一直到时我们找到了「基本情况」。 然后拿到「基本情况」开始往回计算。这个过程我们简称为「由下到上」。
下面我们用 这个过程进行分析。
# 2.2.1 由下到上
由下到上:在每个递归层次上,我们首先递归地调用自身,然后根据返回值进行计算。(依赖返回值)
/**
* 模拟程序执行过程:
* 5 + sum(4)
* 5 + (4 + sum(3)
* 5 + 4 + (3 + sum(2))
* 5 + 4 + 3 + (2 + sum(1))
* ------------------> 到达基本情况 sum(1) = 1 ,开始执行 ③ 行代码
* 5 + 4 + 3 + (2 + 1)
* 5 + 4 + (3 + 3)
* 5 + (4 + 6)
* (5 + 10)
* 15
* <p>
* 由下到上:最终从 1 + 2 + 3 + 4 + 5 计算...
* 递归函数「开始」部分调用自身,这个过程就是找到基本情况),然后根据返回值进行计算。
*/
public int sum(int n) {
if (n < 2) return n; // ① 递归基本情况
int childSum = sum(n - 1); // ② 寻找基本情况
return n + childSum; // ③ 根据返回值运算
}
由下到上的过程其实是一个先寻找基本情况(基本情况),然后根据基本情况计算基本情况的父问题,一直到最后一个父问题计算后返回最终结果。
本示例中基本情况是 sum(1) = 1,基本情况的父问题是 sum(2) = 2 + sum(1)。
由下到上-范式
- 寻找递推关系
- 寻找递归基本情况,跳出时返回基本情况的结果
- 修改递归函数的参数,递归调用
- 使用递归函数的返回值进行计算并返回最终结果
public 返回值 f(参数) {
if (基本情况条件) return 基本情况的结果;
修改参数;
返回值 = f(参数);
最终结果 = 根据参数与返回值计算
return 最终结果;
}
# 2.2.2 由上到下
假如我们换个思路, 中我们把 的结果提取出来 , 每次计算都带着它,这样我们可以先计算当前的数值,然后把计算好的结果传递给下一次计算,这个过程我们称为「由上到下」。
由上到下:在递归层级中,我们根据当前「函数参数」计算出一些值,并在递归调用函数时将这些值传给自身。(依赖函数参数)
/**
* 模拟程序执行过程:
* sum(5, 0)
* sum(4, 5)
* sum(3, 9)
* sum(2, 12)
* sum(1, 14)
* 15
* <p>
* 由上到下:最终从 5 + 4 + 3 + 2 + 1 计算...
* 递归函数「末尾」部分调用自身,根据逻辑先进行计算,然后把计算的中间变量传递调用函数。
* <p>
* 这种在函数末尾调用自身的递归函数叫做「尾递归」
*/
public int sum2(int n, int sum) {
if (n < 2) return 1 + sum;
sum += n;
return sum2(n - 1, sum);
}
由上到下-范式
- 寻找递推关系
- 创建新函数,将「由下到上-范式」中的最终结果计算依赖的中间变量提取为函数的参数
- 寻找递归基本情况,跳出时返回基本情况的结果与中间变量的计算结果(最终结果)
- 根据函数参数与中间变量重新计算出新的中间变量
- 修改参数
- 递归调用并返回(该处的返回由基本情况触发)
public 返回值 f(参数,中间变量) {
if (基本情况条件) return 基本情况的结果与中间变量的计算结果;
中间变量 = 根据参数与中间变量重新计算
修改参数;
return f(参数,中间变量);
}
# 2.2.3 由下到上、由上到下的区别
两者最大的区别在于对中间变量的处理,参与计算的中间变量是参数提供的还是返回值提供的,这个过程最终决定了基本情况的返回值处理逻辑、递归函数的执行位置。
递归函数在计算前先找到基本情况再算还是先算再找基本情况,这个过程也就是「由下到上、由上到下」的本质差异。
# 2.3 优化递归函数
优化点总结为:
充分分析基本情况(跳出条件),避免临界值跳不出递归,导致栈溢出。
分析递归深度,太深的递归容易导致栈溢出。
分析是否有重复计算问题,主要分析函数参数值是否会出现重复,直接代入递归的递推关系中运算即可。如果会出现重复使用数据结构记录。
比如:斐波那契数列 ,如果直接采用该公式进行递归会重复计算很多表达式。
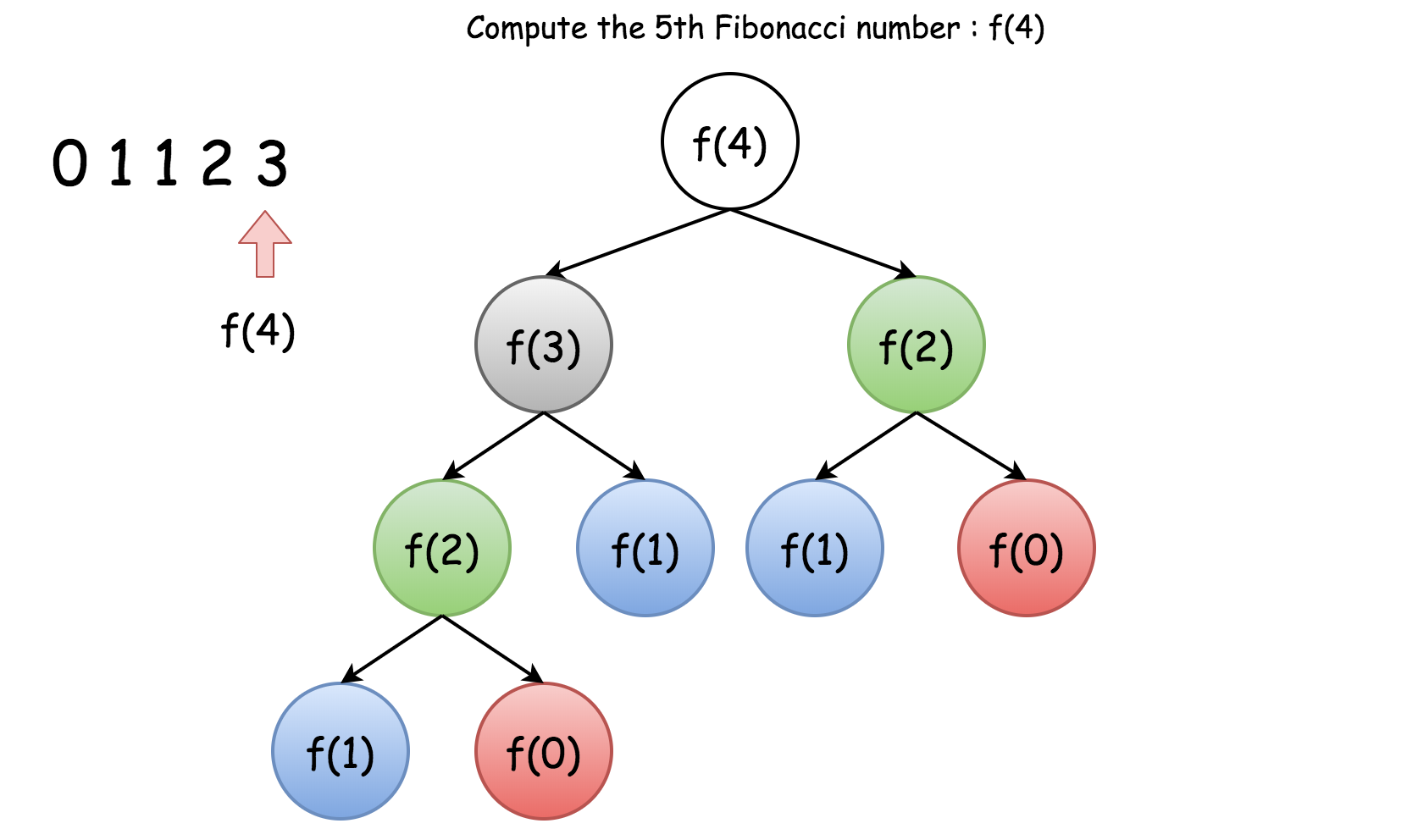
来源于[递归中的重复计算 ]:https://leetcode-cn.com/explore/orignial/card/recursion-i/258/memorization/1211/
分析数据溢出问题
将「由下到上」优化为「由上到下」,再改写为尾递归,再退化为循环结构。因为递归会对栈及中间变量的状态保存有额外的开销。
# 2.4 改为循环
递归本身的风险比较高,实际项目不推荐采用。部分编程语言可以对尾递归进行编译优化(优化为循环结构),比如 Scala 语言。但是部分语言不支持,比如 Java。
函数式编程时推荐尾递归写法并加标识让编译器进行优化,下面是 scala 语言优化的案例:
// Scala 编译前的尾递归写法,并注解为尾递归
@scala.annotation.tailrec
def sum2(n: Int, sum: Int): Int = {
if (n < 2) return sum + n
sum2(n - 1, sum + n)
}
// 编译后优化为循环结果
public int sum2(int n, int sum) {
while (true) {
if (n < 2) return sum + n;
sum += n;
n--;
}
}
一个不是尾递归的案例:
// 并不是最后一行递归调用就是尾递归,下面例子其实是一个由下到上的递归写法,返回值与 n 有关。
def sum(n: Int): Int = {
if (n < 2) return n
return n + sum(n - 1)
}
# 3. 案例实战-递归乘法
对于有些算法,递归比循环实现简单,比如二叉树的前中后序遍历。但是大部分时候循环比递归更直观更容易理解。
下面我们以力扣一个算法题 递归乘法 (opens new window) 进行实战,实战前请花 10 min 时间尝试自我完成。
如果只是局限于看小说似的阅读,现在就可以「ALT+F4」了。 🙈
递归乘法。 写一个递归函数,不使用 * 运算符, 实现两个正整数的相乘。可以使用加号、减号、位移,但要吝啬一些。
示例 1:
输入:A = 1, B = 10
输出:10
示例 2:
输入:A = 3, B = 4
输出:12
public int multiply(int A, int B)
# 3.1 审题思路
乘法本身是加法的变种,A * B = A 个 B 相加。
寻找基本情况的条件为:A 个 B 相加一次 A - 1,A 如果为 1 时即找到最后一个 B 。
首先我们用循环完成。
public int multiplyFor(int A, int B) {
int sum = 0;
while (A-- > 0) sum += B;
return sum;
}
# 3.2 尝试递归
寻找递推关系 ,基本情况条件为 时表示找到最后一个
套入「由下到上」的范式如下:
- 寻找递推关系
- 寻找递归基本情况,跳出时返回基本情况的结果 -> B
- 修改递归函数的参数,递归调用 -> multiply(A - 1, B) return sum
- 使用递归函数的返回值进行计算并返回最终结果 -> sum + B
public int multiply(int A, int B) {
if (A < 2) return B; // 跳出时返回基本情况的结果
int sum = multiply(A - 1, B); // 先递归
return sum + B; // 再计算,依赖递归的返回值
}
尝试转换为递归「由上到下」(尾递归),依赖中间结果(每次的和),先计算再递归。
, 为已经计算了的 个 的和。
- 寻找递推关系
- 创建新函数,将「由下到上-范式」中的最终结果计算依赖的中间变量提取为函数的参数 -> multiply1Help 函数 sum 为中间变量
- 寻找递归基本情况,跳出时返回基本情况的结果与中间变量的计算结果(最终结果) -> return B + sum
- 根据函数参数与中间变量重新计算出新的中间变量 -> sum += B
- 修改参数 -> A - 1
- 递归调用并返回(该处的返回由基本情况条件触发)-> B + sum
public int multiply1(int A, int B) {
return multiply1Help(A, B, 0);
}
public int multiply1Help(int A, int B, int sum) {
if (A < 2) return B + sum; // 跳出时返回基本情况的结果与中间变量的计算结果
sum += B; // 根据函数参数与中间变量重新计算出新的中间变量
return multiply1Help(A - 1, B, sum);// 由基本情况条件触发决定,最终返回 B + sum
}
至此,两个递归写法已实现,实际编码中「由上到下」比「由下到上」更容易理解,因为我们的思维从上向下思考容易,但是逆着思考就比较抽象了。 这个抽象过程的训练需要大量的练习,末尾推荐了部分递归的算法题。
# 3.3 尝试优化
分析上述实现的两个递归时间复杂度为 ,,考虑如何优化时间复杂度。
- 如果 A > B ,处理 A 次,因此考虑使用 作为循环次数。比如 时可优化 100 倍
- 分析重复计算问题,目前没有。
- 分析参数的边界问题,目前没有。题目给定约束都是正整数。
- 优化时间复杂度,重新分析递推关系为 ,直到 等于 时, 就是最终结果,我们基于二进制的位移操作进行优化, 但是考虑如果是奇数除以 时会丢失一个 ,这样复杂度优化为
优化过程示例:a * b = (a/2) * (b*2)
偶数为循环次数的运算过程
8 * 9
4 * 18
2 * 36
1 * 72
72
奇数为循环次数的运算过程
7 * 9
9 + (3 * 18) -> 7/2 时丢失一个 9
9 + 18 + (1 * 36) -> 3/2 时丢失一个 18
9 + 18 + 36
63
将上述过程转换为「由上到下」尾递归代码实现(你可以尝试「由下到上」实现,可以套入范式进行验证):
public int multiply2(int A, int B) {
return (A < B) ? multiply2Help(A, B, 0) : multiply2Help(B, A, 0); // 寻找最小循序次数
}
// missPart 为奇数除以 2 时丢失的部分
public int multiply2Help(int A, int B, int missPart) {
if (A < 2) return missPart + B; // 最终结果 = 丢失的部分 + 最终 B 的结果
missPart += (A & 1) == 1 ? B : 0; // 是否为奇数,奇数时记录丢失的部分
return multiply2Help(A >> 1, B << 1, missPart); // 位移运算优化
}
# 4. 案例实战-青蛙跳台阶
一只青蛙一次可以跳上 1 级台阶,也可以跳上 2 级台阶。求该青蛙跳上一个 n 级的台阶总共有多少种跳法。 n = 0 时忽略。
寻找基本情况:剩余一个台阶时只能有一种跳法 ,剩余两个台阶时只能有两种跳法 ,或者剩余 3 个台阶时有 3 种跳法(1-1-1、1-2、2-1)
寻找递推关系:如果跳 1 级台阶就少一个,结果为 种,如果跳 2 级台阶就少 2 个,结果为 种。
所以推导递推关系为优化递归:考虑重复计算问题,因为涉及减法运算,肯定会出现重复代入 计算,因此考虑使用数据结构保存计算过的结果。分析数据溢出问题,如果没有给定约束条件,要考虑返回跳法是否会溢出。
由下到上的范式套入实现:
/**
* - 寻找递推关系 f(n)=f(n-1)+f(n-2)
* - 寻找递归基本情况,跳出时返回基本情况的结果 f(1) = 1,f(2) = 2
* - 修改递归函数的参数,递归调用 -> 套入递推关系,当前 n 台阶跳法为 count=f(n-1)+f(n-2)
* - 使用递归函数的返回值进行计算并返回最终结果 -> 递归返回跳法数 count 即为最终结果
*/
public int numWays1(int n) {
if (n == 1) return 1;
if (n == 2) return 2;
int count = numWays1(n - 1) + numWays1(n - 2);
return count;
}
// 优化思路,2 个 if 可有优化 为 if (n <= 2) return n; 减少执行次数
// 递归函数重复计算问题,使用临时变量保存
private final Map<Integer, Integer> statusRecord = new HashMap<>();
public int numWays(int n) {
if (n <= 2) return n; // if 判断比计算状态判断开销小,因此先进行 if
final Integer integer = statusRecord.get(n); // 计算状态判断,已经计算直接返回
if (integer != null) return integer;
int count = numWays(n - 1) + numWays(n - 2);
statusRecord.put(n, count); // 计算的结果保存至状态表
return count;
}
// 至此除了数据溢出问题没有处理,重复计算已优化。
由上到下的范式套入实现:
/**
* 由上到下的范式套入实现:
*
* - 寻找递推关系
* 由下到上递推关系为,f(n) = f(n-1) + f(n-2) 相当于从 n-1 的计算过程,先从 n 找到 1,然后在从 1 累加到 n 的过程
* 我们改为从 1-n 的过程,f(i+1) = f(i) + f(i-1) , i+1==n 时计算结束,累加的过程变量需要我们提取为中间变量参数
*
* - 创建新函数,将「由下到上-范式」中的最终结果计算依赖的中间变量提取为函数的参数
* 将 f(i),f(i-1) 的变量保存,初始调用我们使用 f(2) = f(1) + f(0) = 1 + 1 作为初始状态
*
* - 寻找基本情况,跳出时返回基本情况的结果与中间变量的计算结果(最终结果)-> if (i >= n) return a + b;
*
* - 根据函数参数与中间变量重新计算出新的中间变量
* f(i) = f(i-1) + f(i-2) = a + b
* f(i+1) = f(i) + f(i-1) = (a+b) + b
*
* - 修改参数 -> i + 1 递进一步
*
* - 递归调用并返回(该处的返回由基本情况条件触发)
*/
public int numWaysTail(int n) {
if (n < 2) return n;
return numWaysTailHelp(n, 2, 1, 1);
}
private int numWaysTailHelp(int n, int i, int a, int b) {
if (i >= n) return a + b;
return numWaysTailHelp(n, i + 1, a + b, a);
}
// 因为是从 1-n 的计算,所以不会出现重复计算过程。
尾递归优化为循环结构:(也称为动态规划 (opens new window))
public int numWaysFor(int n) {
if (n < 2) return n;
int i = 2; int a = 1; int b = 1; // 与尾递归 numWaysTailHelp 一致
int count = a + b; // 保存次数,将尾递归的返回值提取为变量
while (i <= n) { // 1-n 的过程
// 因为 f(i) = f(i-1) + f(i-2) = a + b
// 下次迭代时 f(i+1) = f(i) + f(i-1) = (a+b) + b
count = a + b;
b = a;
a = count;
i++;
}
return count;
}
# 5. 再谈由上到下、由下到上
一般情况,我们说递归时指的是「由下到上」,因为「由上到下」的过程往往需要创建新函数去完成,更甚至「由上到下」其实就是循环结构封装为函数式编程的写法,也叫尾递归。 由下到上转换为由上到下的过程其实就是转换为循环结构写法的过程。
递归难以理解的地方在于由下到上的过程,其实细化该难点可以分为「基本情况」->「改变参数继续递归」->「拿到递归返回值与当前参数计算」。 实际编码中我们只要按上述提到的范式进行代码编写,上述示例中的基本情况比较单一,中间变量也只涉及一个,对于复杂的跳出及中间变量的处理只要按范式步骤进行分析然后再优化一定可以写出一个递归函数。
对于递推关系的寻找过程,没有范式可寻,需要见多识广(🙉刷刷刷🙉),不断总结。
# 6. 递归算法推荐
# 总结
简单的总结为:
- 你要写哪种类型的递归,从上算还是从下算,这决定了你如何确认递推关系
- 分析基本情况
- 寻找递推关系,在递推关系中提取中间变量
- 套入上文中的递归范式
- 按上文中的优化点进行优化
题外话:对于自上而下的计算不是必须创建新函数去传入中间变量,因为有时我们可以使用全局变量保存、或者直接修改当前递推关系中的变量即可。 推荐使用总结内容「由上到下、由下到上、循环结构」三种方法完成力扣-206. 反转链表 (opens new window)
# 参考
本内容随着对数据结构算法的深入,持续更新。
更多相关专栏内容汇总:

← 算法技巧总结