专栏原创出处:github-源笔记文件 (opens new window) ,github-源码 (opens new window),欢迎 Star,转载请附上原文出处链接和本声明。
Java JVM-虚拟机专栏系列笔记,系统性学习可访问个人复盘笔记-技术博客 Java JVM-虚拟机 (opens new window)
# 一、Java 源代码怎么执行的
许多 Java 虚拟机的执行引擎在执行 Java 代码的时候都是解释执行(通过解释器执行)和编译执行(通过即时编译器产生本地代码执行)混合运行。
大体流程为:
- 编写 java 文件源码
- 通过 javac 编译器将 java 源码编译为字节码流
- 通过解释器解释执行字节码
- 随着时间推移,即时编译器 (JIT) 介入,把越来越多的字节码编译成本地代码(机器码)执行
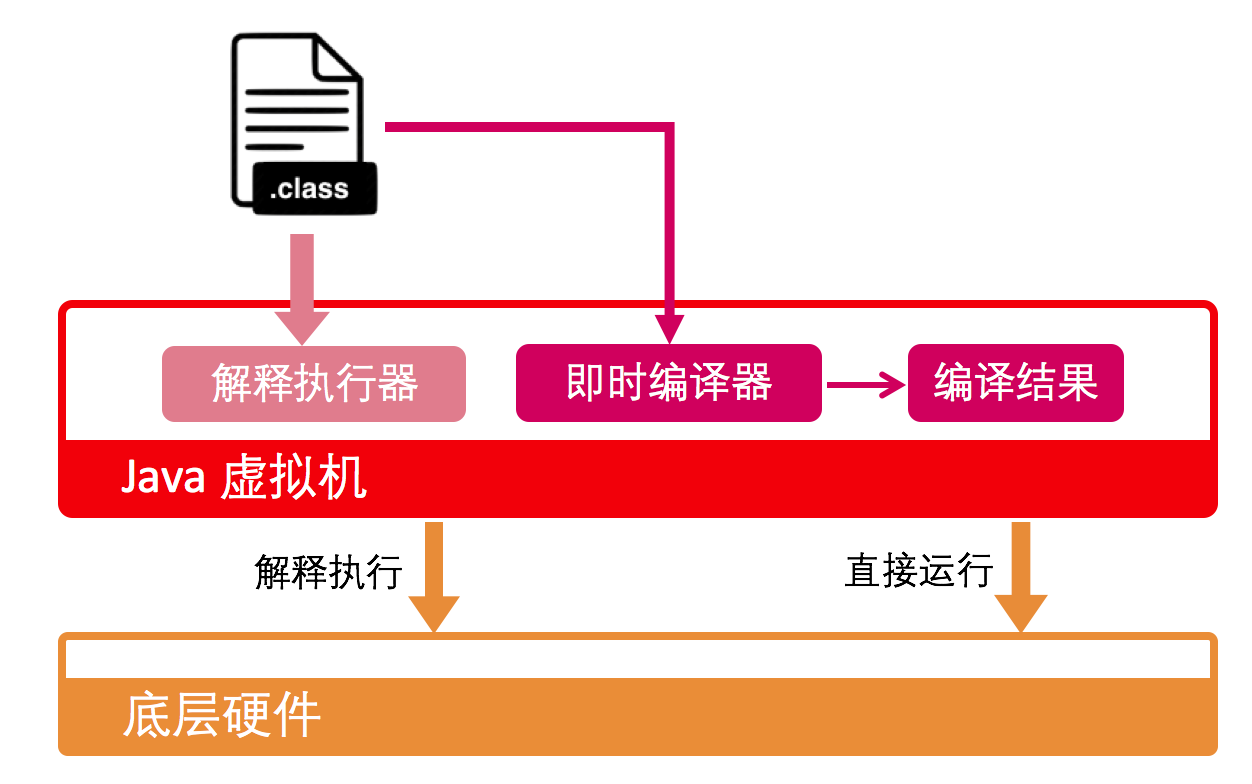
本文中无特殊说明,编译器指即时编译器,即在运行期间的编译。
# 二、解释器是怎么解释字节码流执行的
我们使用 javac 编译器编译完后会生成字节码流,这些字节码解释执行方式有 2 种。一种是基于栈的指令集,一种是基于寄存器的指令集。
比如一个 1 + 1 的计算。
基于栈的指令集时:
iconst_1 将 1 放入栈顶
iconst_1 将 1 放入栈顶
iadd 将栈顶的 2 个数相加后结果放入栈顶
istore_0 将相加的结果放入局部变量表
基于寄存器的指令集时:
mov eax,1 把 EAX 寄存器的值设为 1
add eax,1 再把这个值加 1 ,结果保存在了 EAX 寄存器
两套指令集的优缺点:
- 基于栈的指令集优点是可移植,因为寄存器由硬件直接提供,受到硬件的约束。
- 基于栈的指令集缺点理论上执行速度可能较慢,出栈入栈本身就涉及了大量的指令,而且栈是在内存中实现的。
实际中基于栈的指令集会被虚拟机优化,比如使用即时编译,常用操作映射到寄存器。
# 三、编译器是如何将字节码编译为本地机器码的
服务端编译器和客户端编译器的编译过程是有所差别。
对于客户端编译器来说:
它是一个相对简单快速的三段式编译器,主要的关注点在于局部性的优化,而放弃了许多耗时较长的全局优化手段。
在第一个阶段,一个平台独立的前端将字节码构造成一种高级中间代码表示(High-Level Intermediate Representation,HIR,即与目标机器指令集无关的中间表示)。 HIR 使用静态单分配(Static Single Assignment,SSA)的形式来代表代码值,这可以使得一些在 HIR 的构造过程之中和之后进行的优化动作更容易实现。 在此之前编译器已经会在字节码上完成一部分基础优化,如方法内联、常量传播等优化将会在字节码被构造成 HIR 之前完成。
在第二个阶段,一个平台相关的后端从 HIR 中产生低级中间代码表示(Low-Level Intermediate Representation,LIR,即与目标机器指令集相关的中间表示), 而在此之前会在 HIR 上完成另外一些优化,如空值检查消除、范围检查消除等,以便让 HIR 达到更高效的代码表示形式。
最后的阶段是在平台相关的后端使用线性扫描算法(Linear Scan Register Allocation)在 LIR 上分配寄存器,并在 LIR 上做窥孔(Peephole)优化,然后产生机器代码。
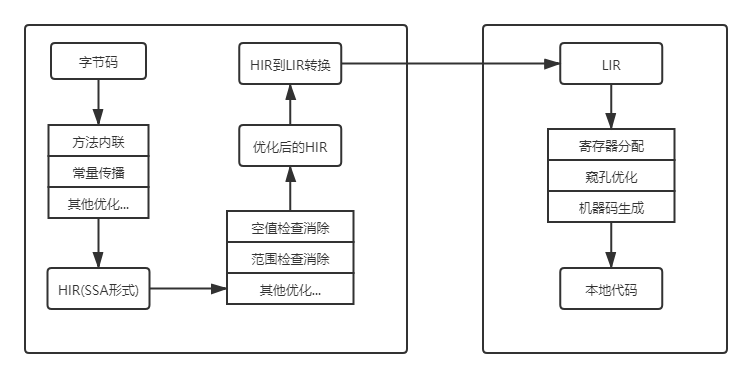
对于服务端编译器来说:
服务端编译器则是专门面向服务端的典型应用场景,并为服务端的性能配置针对性调整过的编译器,也是一个能容忍很高优化复杂度的高级编译器,几乎能达到 GNU C++ 编译器使用-O2 参数时的优化强度。 它会执行大部分经典的优化动作,如:无用代码消除、循环展开、循环表达式外提、消除公共子表达式、常量传播、基本块重排序等, 还会实施一些与 Java 语言特性密切相关的优化技术,如范围检查消除、空值检查消除等。 另外,还可能根据解释器或客户端编译器提供的性能监控信息,进行一些不稳定的预测性激进优化,如守护内联、分支频率预测等
服务端编译采用的寄存器分配器是一个全局图着色分配器,它可以充分利用某些处理器架构(如 RISC)上的大寄存器集合。 以即时编译的标准来看,服务端编译器无疑是比较缓慢的,但它的编译速度依然远远超过传统的静态优化编译器, 而且它相对于客户端编译器编译输出的代码质量有很大提高, 可以大幅减少本地代码的执行时间,从而抵消掉额外的编译时间开销,所以也有很多非服务端的应用选择使用服务端模式的 HotSpot 虚拟机来运行。
# 四、为什么同时使用了解释器与编译器
解释器与编译器两者各有优势:
当程序需要迅速启动和执行的时候,解释器可以首先发挥作用,省去编译的时间,立即运行
当程序启动后,随着时间的推移,编译器逐渐发挥作用,把越来越多的代码编译成本地代码,这样可以减少解释器的中间损耗,获得更高的执行效率
当程序运行环境中内存资源限制较大,可以使用解释执行节约内存(如部分嵌入式系统中和大部分的 JavaCard 应用中就只有解释器的存在)
当程序运行环境中内存资源限制较小,可以使用编译执行来提升效率
# 五、提前编译器
前面仅说明了即时编译器,其实还有一种提前编译器,在我们编译字节码时直接将部分字节码生成本地代码。
JDK 9 引入了用于支持对 Class 文件和模块进行提前编译的工具 Jaotc,以减少程序的启动时间和到达全速性能的预热时间, 但由于这项功能必须针对特定物理机器和目标虚拟机的运行参数来使用,加之限制太多,Java 开发人员对此了解、使用普遍比较少。
提前编译器的两条分支:
做与传统 C、C++ 编译器类似的,在程序运行之前把程序代码编译成机器码的静态翻译工作
把原本即时编译器在运行时要做的编译工作提前做好并保存下来,下次运行到这些代码(比如公共库代码在被同一台机器其他 Java 进程使用)时直接把它加载进来使用
Android 安装包如果提前编译后,体积会变大。如果不提前编译启动运行可能会变慢。目前有一种优化手段就是空闲时间编译。
# 六、即时编译器的种类
JDK 10 前,HotSpot 拥有两款即时编译器,客户端即时编译器 C1。服务端即时编译器 C2。
从 JDK 10 起,HotSpot 新增一个 Graal 目标是代替服务端即时编译器 C2。